Deep Interest Network
1. 问题
在推荐系统领域中,通常的做法是将UserProfile、UserBehaviors、CandidateItem、ContextFeatures分别通过Embedding之后,从高维稀疏特征转化为低维稠密特征, 然后通过神经网络对这些特征进行学习,输出对CandidateItem的CTR。通常的推荐系统神经网络模型结构如下图所示:

上述传统做法的一大缺点是将用户所有的行为记录UserBehaviors都平等地对待,对应的模型中就是 average poolingn 或者 sum pooling,将用户交互过的Item的embedding vector进行
简单的平均或者加和来表示这个用户历史行为的 vector,可能稍微加点trick的话,对不同时间的行为加上一个 time decay 系数,对兴趣进行时间衰减。
但是,通过我们的一系列行为中,有一部分是无效或者叫暂时兴趣,只是在当时的那个时刻存在之后就消失的兴趣,在上述传统 average pooling 中也将这部分兴趣点平等对待地考虑了进来,
这无疑对用户的兴趣点捕捉是存在问题的,因此这篇论文提出了将 Attention机制 应用于推荐系统领域中。主要解决的是:让模型对不同时刻的交互行为学习不同的权重,而不是平等对待每一个历史交互行为
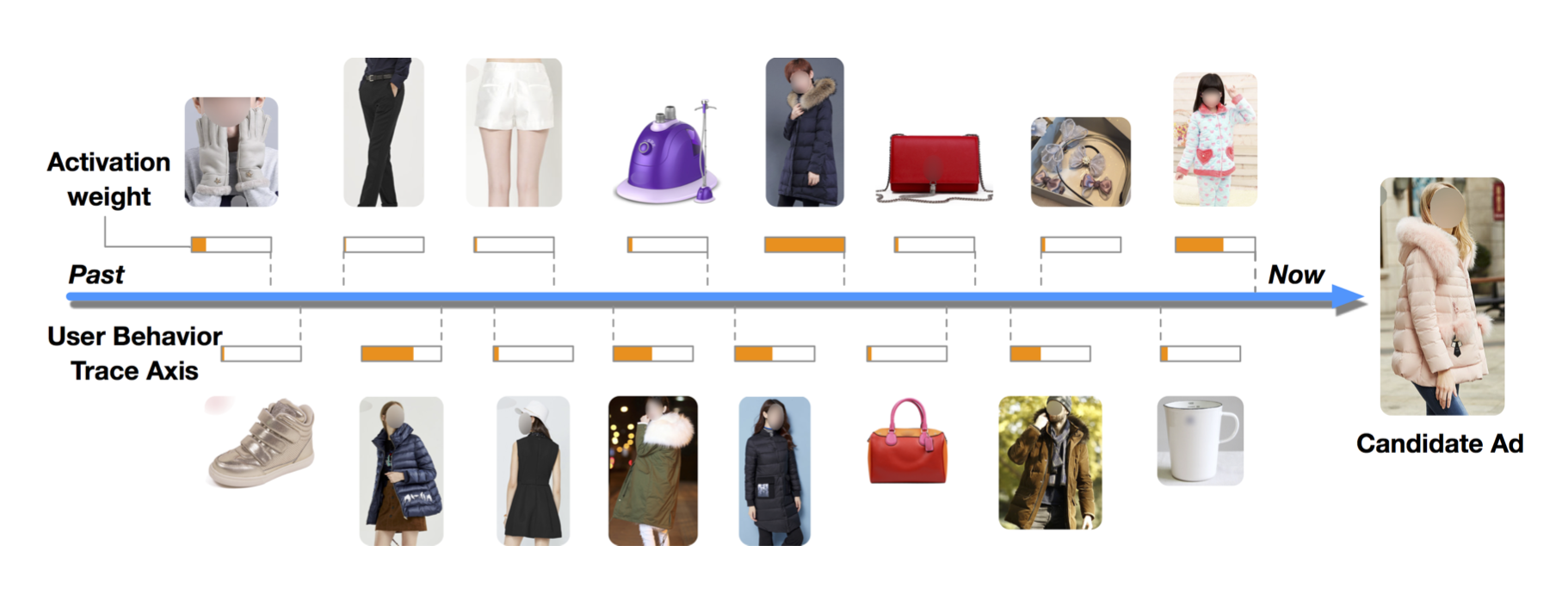
如上图所示,用户历史的购买鞋子行为对推荐大衣的广告的影响很小。
2. Attention机制
Paper中提出了新的模型 Deep Interest Network, DIN 用来解决传统对用户行为一概而论的缺点。模型结构如下:
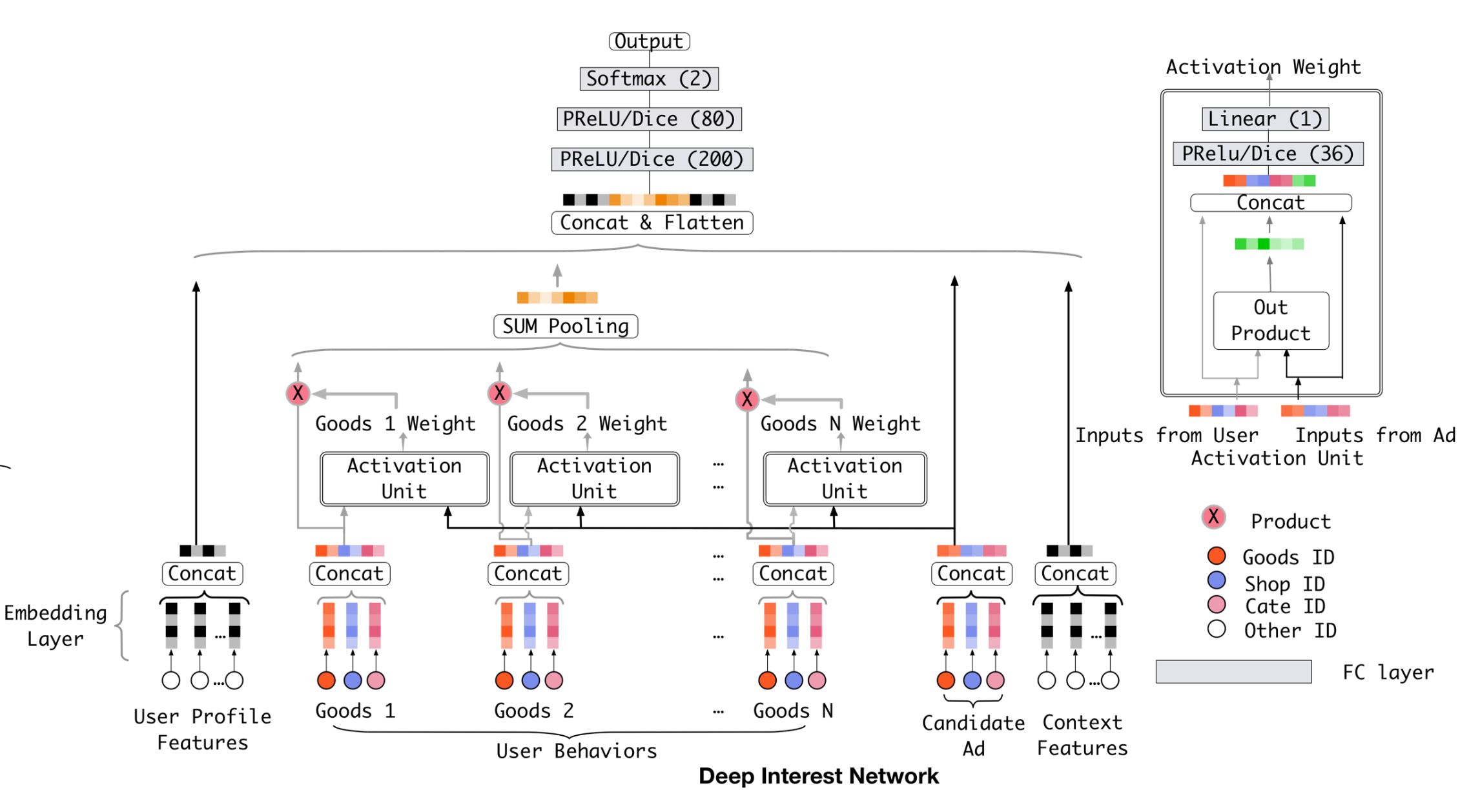
其中不同的地方主要集中在对用户历史行为的学习部分,因此这里不再赘述其他部分,单独只说对用户历史行为的学习部分(引入Attention的部分)。
- Embedding层都是一样的,Item和其Categroy都是单独进行Embedding,然后进行Concat,这样每个
ItemVector都是由其本身的ID和cate组合而成 - CandidateItem,即待评估ctr的Item同其他Item的Embedding操作是一样的,共用相同的Embedding Matrix,生成
CandidateVector - 将
ItemVector和CandidateVector一起传入到一个 Activate Unit 中,学习历史交互Item和CandidateItem之间的关联性weight(归一化到[0, 1]),即Item这个历史行为对推荐CandiateItem的影响权重有多少 - 这里的 Activate Unit 其实就是 Attention机制,里面具体的操作在后续 5.代码逻辑 中再详细描述
- 将学习到的Item 和 CandidateItem之间的weight同
ItemVector进行 element-wise 乘 - 所有的历史交互Item进行
sum pooling,得到一个同ItemVector相同纬度的BehaviorsVector来表示用户历史兴趣对待推荐 CandidateItem 的分布 - 将
UserProfilesFeatures、BehaviorsVector、CandidateVector、ContextFeatures一起再输入到神经网路中学习一些特征交叉、特征组合,最终输出预测的ctr
论文中公式表述Attention的公式(3) 如下:
其中: ${ e_1, e_2, …, e_H }$ 是长度为 H 的用户 U 历史行为embedding vector列表;$v_A$是Item A的embedding vector,$v_U(A)$表示在候选Item是 A 的时候,对用户历史学习到的用户表示向量。
3. Metrics
其中 $n$ 是用户数量,$ \sharp impression_i$ 和 $AUC_i$ 是第 $i$ 个用户的impression和$AUC$
4. 激活函数
无论是PReLU还是ReLU的控制函数都是一个阶跃函数,其变化点在 $0$ 处,意味着面对不同的输入这个变化点是不变的。 实际上神经元的输出分布是不同的,面对不同的数据分布采用同样的策略可能是不合理的,因此提出的 Dice 中改进了这个控制函数, 让它根据数据的分布来调整,这里我们选择了统计神经元输出的均值和方差来描述数据的分布:
其中:训练阶段$E[s]$ 和 $Var[s]$ 是每个mini-batch的均值和方差;测试阶段 $E[s]$ 和 $Var[s]$ is calculated by moving averages E[s] and Var[s] over data. $\epsilon$是一个很小的常数,论文中设置为 $10^{-8}$。
Ps:测试阶段这一句没理解
5. 代码逻辑
先说格式:
- train set format: list((用户ID, 历史购买序列, 再次购买的商品, label))
- test set format: list((用户ID, 历史购买序列, (购买商品, 没购买商品)))
其中的各种ID都已经映射到了index,历史购买序列是一个index序列,label非0即1
Attention机制部分:
1 |
|