科学上网搭建方法
1. 自建ss服务器教程
自建ss/ssr教程很简单,整个教程分三步:
- 购买VPS服务器
- 一键部署VPS服务器
- 一键加速VPS服务器
1.1 购买VPS服务器
VPS服务器需要选择国外的,首选国际知名的vultr,速度不错、稳定且性价比高,按小时计费,能够随时开通和删除服务器,新服务器即是新ip。vultr官网:https://my.vultr.com/
自建ss/ssr教程很简单,整个教程分三步:
VPS服务器需要选择国外的,首选国际知名的vultr,速度不错、稳定且性价比高,按小时计费,能够随时开通和删除服务器,新服务器即是新ip。vultr官网:https://my.vultr.com/
先看两个问题:
Tensorflow API提供了Cluster、 Server以及 Supervisor来支持模型的分布式训练。 关于Tensorflow的分布式训练介绍可以参考 Distributed Tensorflow。
简单的概括说明如下:
embedding中牢记feature_batch中的value表示的都是embedding矩阵中的index
使用embedding_lookup函数来实现Emedding,如下:
1 | # embedding matrix 4x4 |
Google Play 用的深度神经网络推荐系统,主要思路是将 Memorization(Wide Model) 和 Generalization(Deep Model) 取长补短相结合。
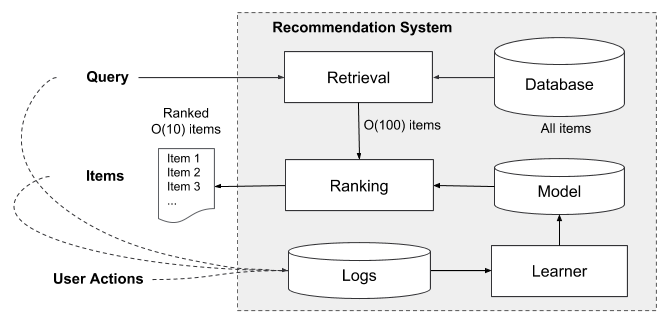
先来看一下推荐系统的整体架构,由两个部分组成,检索系统(或者说候选生成系统) 和 排序系统(排序网络)。首先,用 检索(retrieval) 的方法对大数据集进行初步筛选,返回最匹配 query 的一部分物品列表,这里的检索通常会结合采用 机器学习模型(machine-learned models) 和 人工定义规则(human-defined rules) 两种方法。从大规模样本中召回最佳候选集之后,再使用 排序系统 对每个物品进行算分、排序,分数 $P(y|x)$,$y$ 是用户采取的行动(比如说下载行为),$x$ 是特征,包括
NFM充分结合了FM提取的二阶线性特征与神经网络提取的高阶非线性特征。总得来说,FM可以被看作一个没有隐含层的NFM,故NFM肯定比FM更具表现力。
FM预测公式:
FFM(Field Factorization Machine)是在FM的基础上引入了场(Field)的概念而形成的新模型。
在FM中计算特征 $x_i$ 与其他特征的交叉影响时, 使用的都是同一个隐向量 $v_i$ 。
而FFM将特征按照事先的规则分为多个场(Field), 特征 $x_i$ 属于某个特定的场$f$。
每个特征将被映射为多个隐向量 $v_{i,1}, v_{i,2}, \cdots, v_{i,f}$ , 每个隐向量对应一个场。
当两个特征 $x_i, x_j$ 组合时, 用对方对应的场对应的隐向量做内积: