HashEmbedding&QREmbedding
1. HashEmbedding
paper: hash-embeddings-for-efficient-word-representations.pdf
1.1 简介
Hash Embedding可以看作是普通word embedding和通过随机hash函数得到的词嵌入的interposition(插补)。 在Hash Embedding中,每个token由k个d维embedding vectors和一个k维weight vector表示,token的最终d维表示是两者的乘积。
实验表明,Hash Embedding可以轻松处理包含数百万个token的庞大词汇表。 使用Hash Embedding时,无需在训练前创建字典,也无需在训练后进行任何形式的词汇修剪。 使用Hash Embedding训练的模型表现出的性能至少与在各种任务中使用常规Embedding训练的模型具有相同的性能水平。
1.2 背景
经典的word embedding表示方法存在的问题:词表过大时,极大的增加神经网络参数量。
传统解决词表过大的方法:
- 忽略低频词、停用词。问题:有些低频词或停用词在特定任务中可能是关键信息。例如“and”在一个逻辑相关的任务中是非常重要的。
- Remove non-discriminative tokens after training:选取最有效的token。问题:性能下降、很多任务不合适
- 压缩词向量:有损压缩(量化等)
使用Hash Embedding能有效避免上述方法的问题,并且有很多优点:
- 使用Hash Embedding时,无需事先创建字典,并且该方法可以处理动态扩展的词汇表。
- Hash Embedding具有能够隐式词汇修剪的机制。
- Hash Embedding基于Hash,但具有可训练的机制,可以处理有问题的冲突。
- Hash Embedding执行类似于乘积量化的操作, 但是不是所有token共享一个单一的小密码本,而是每个token都可以获取非常大的密码本中的一些元素。
1.3 流程
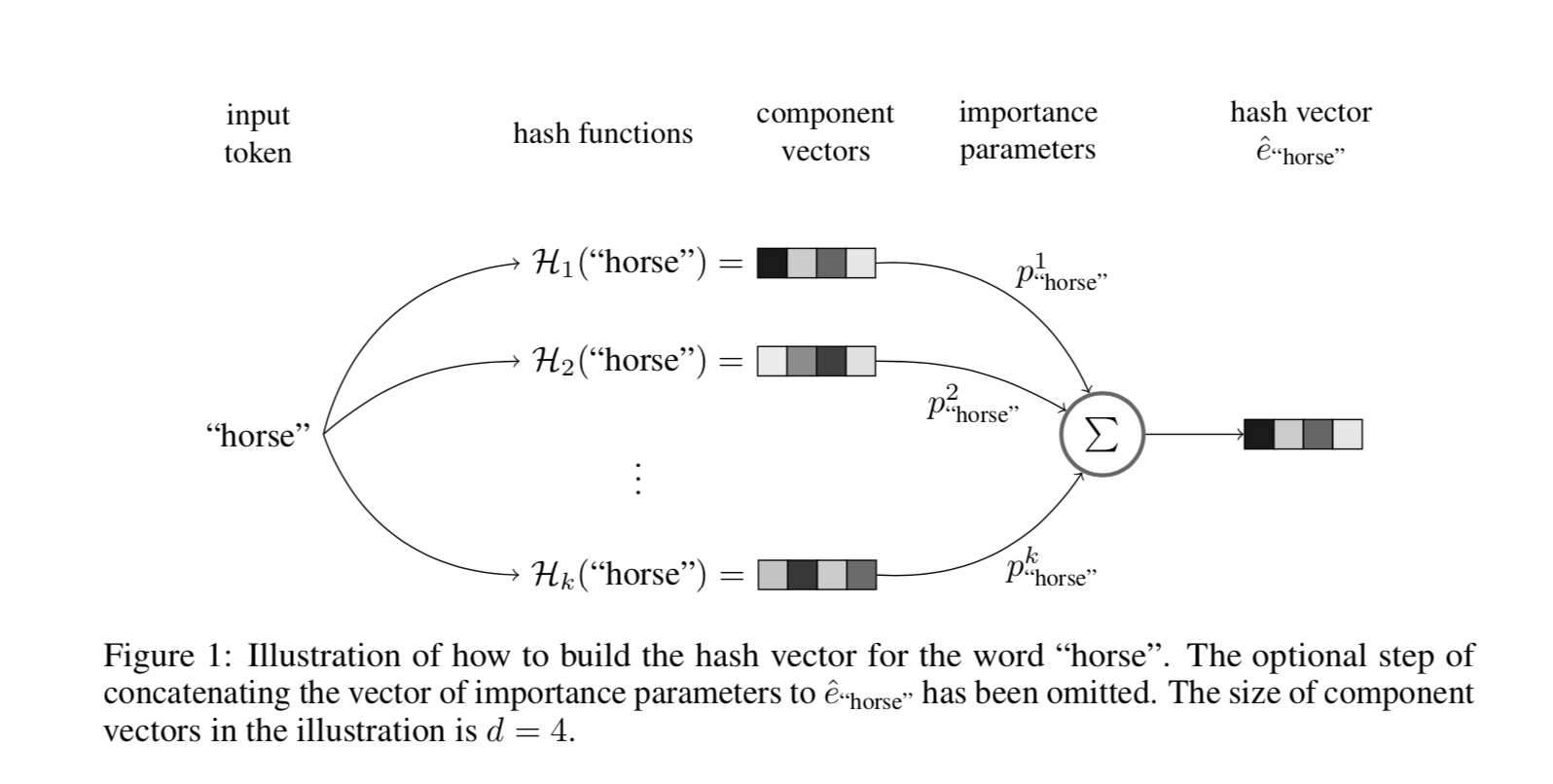
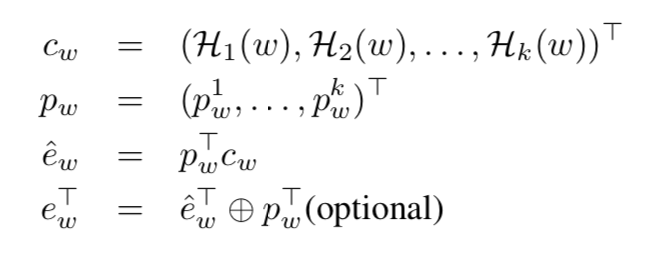
- 多个Hash函数从同一个Embedding Table中获取 embedding vector
- 将获取到的多个 embedding vector 进行加权求和 sum embedding vector
- (可选)将权重和 sum embedding vector进行连接,作为 final embedding vector
2. QREmbedding
paper: Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems
2.1 流程

需要:一个整除Embedding Table,一个取余Embedding Table,超参数m
- 原始index分别做除法(地板除)、取余得到:
j = index // m,k = index % m - j从整除Embedding Table中获得 embedding vector
vj - k从取余Embedding Table中获得 embedding vector
vk - 将
vj和vk进行element-wise reduce合并,可以是加、乘……