Neural Factorization Machines for Sparse Predictive Analytics笔记
NFM充分结合了FM提取的二阶线性特征与神经网络提取的高阶非线性特征。总得来说,FM可以被看作一个没有隐含层的NFM,故NFM肯定比FM更具表现力。
FM预测公式:
NFM预测公式:
其中第$1$项与第$2$项是与FM相似的线性回归部分,第3项是NFM的核心部分,它由一个如下图所示的网络结构组成:
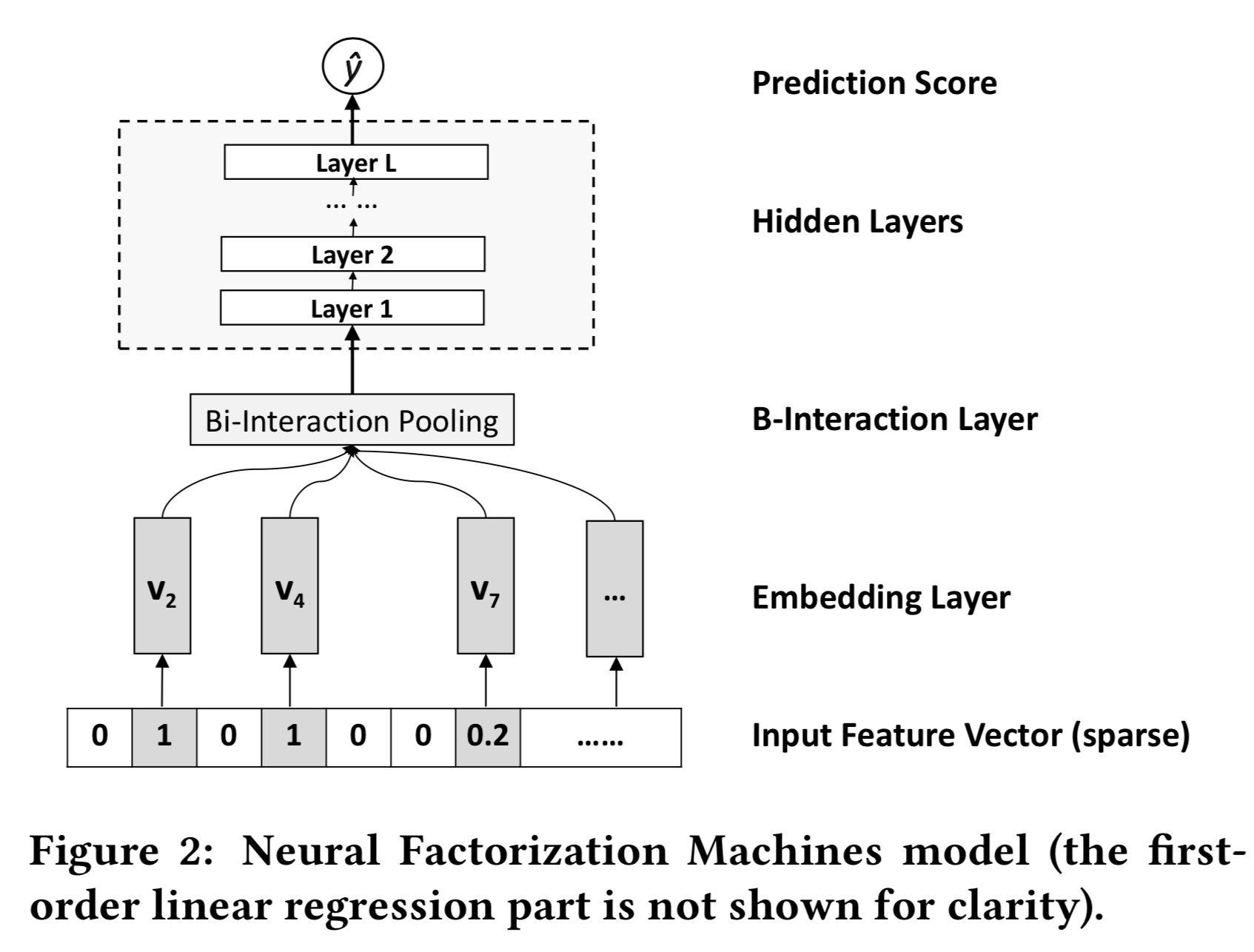
- Embedding Layer
- 该层是一个全连接层,将稀疏的向量给压缩表示。假设我们有 $v_i \in R^k$ 为第 $i$ 个特征的embedding向量,那么在经过该层之后,我们得到的输出为 $ \lbrace x_1 v_1, \cdots, x_n v_n \rbrace$, 注意,该层本质上是一个全连接层,不是简单的
embedding lookup。
- 该层是一个全连接层,将稀疏的向量给压缩表示。假设我们有 $v_i \in R^k$ 为第 $i$ 个特征的embedding向量,那么在经过该层之后,我们得到的输出为 $ \lbrace x_1 v_1, \cdots, x_n v_n \rbrace$, 注意,该层本质上是一个全连接层,不是简单的
Bi-Interaction Layer
- 上层得到的输出是一个特征向量的
embedding的集合,本层本质上是做一个pooling的操作,让这个embedding向量集合变为一个向量,公式如下:
- 其中 $\bigodot$ 代表两个向量对应的元素相乘。显然,该层的输出向量为 $k$ 维,本层采用的
pooling方式与传统的max pool和average pool一样都是线性复杂度的,上式可以变换为:
- 上式中用 $v_2$ 来表示 $v \bigodot v$ ,其实本层本质上就是一个
FM算法。
- 上层得到的输出是一个特征向量的
- Hidden Layer
- 普通的全连接层。
- Prediction Layer
- 将
Hidden Layer的输出经过全连接层,得到最终的Score。
- 将
NFM_tensorflow实现代码:
1 | # this is code |