推荐系统HandBook Chapter2 推荐系统中的数据挖掘方法
数据挖掘的过程一般由三个连续执行的步骤组成:数据预处理、数据分析和结果解释。
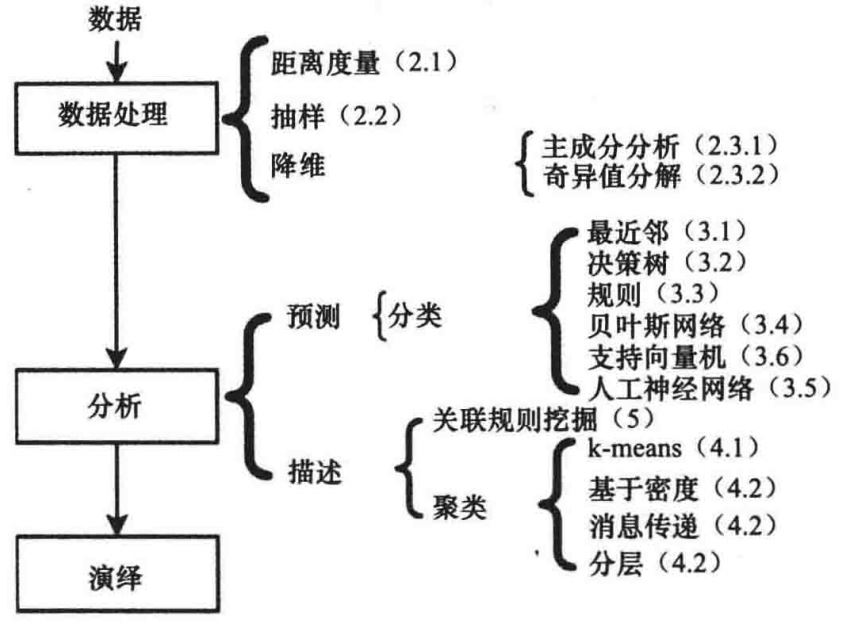
数据预处理
相似度度量方法
- 欧几里德距离
- 马氏距离
其中$ \sigma $是数据的协方差矩阵。
- 余弦度量
- 皮卡逊相关性系数
抽样
根据抽样是否放回,可以分为:
- 有放回抽样
- 无放回抽样
根据抽样方法,可以分为:
- 简单随机抽样
- 每个样本单位被抽中的概率相等,样本的每个单位完全独立,彼此间无一定的关联性和排斥性。
- 系统(等距)抽样
- 将总体中的所有单位按一定顺序排列,在规定的范围内随机地抽取一个单位作为初始单位,然后按事先规定好的规则确定其他样本单位。
- 分层抽样
- 将抽样单位按某种特征或某种规则划分为不同的层,然后从不同的层中独立、随机地抽取样本。
- 整群抽样
- 将总体中若干个单位合并为组,抽样时直接抽取群,然后对中选群中的所有单位全部实施调查。
除非数据集足够大,否则交叉验证可能不可信
降维
推荐系统反复出现的问题:
- 稀疏:只有几个有限的特征有值,其他大部分为零;
- 维度灾难:高维空间并没有给结果带来正相关;
推荐系统中最相关的降维算法,这些技术可以单独作为推荐方法使用,或者作为其他技术预处理的步骤。
- 主成份分析(PCA)
- 获得一组有序的成分列表,其根据最小平方误差计算出变化最大的值;
- 列表中第一个成分代表的变化量要比第二个成分所代表的变化量大,以此类推;
- 通过忽略变化贡献较小的成分来降低维度;
- 奇异值分解(SVD)
- 一大优势是有增量算法来计算近似的分解;
具体降维算法详细内容见—>这里的学习小结
去噪
去噪是预处理步骤中非常重要的一步,其目的是在最大化信息量时去除掉不必要的影响。
噪声的分类:
- 自然的噪声
- 用户在选择偏好反馈时无意产生的
- 恶意的噪声
- 用户为了偏离结果在系统中故意引入的
通过预处理步骤来提高精确度能够比复杂的算法优化效果要好得多
分类
最近邻
给出一个要分类的点,kNN分类器能够从训练记录中发现k个最近的点,然后按照它最近邻的类标签类确定所属类标签。
选择k值的问题:
- k值太小,分类可能对噪声点太敏感;
- k值太大,近邻范围可能会包含其他类中太多的点;
决策树
决策树的优点:构建代价比较小并且在分类未知的对象方面速度比较快;在维持精度的同时,能够容易解释。
推荐系统中使用决策树:
- 用在基于模型的方法中;
- 作为物品排序的工具。
基于规则的分类
规则的产生途径:
- 从数据中直接抽取规则,例子为RIPPER或CN2
- 从其他分类模型中间接抽取,例如决策树模型或神经模型
不流行、很难建立完整的规则
贝叶斯分类器
朴素贝叶斯收孤立噪声点和不相关属性的影响小,且在概率估算期间可以通过忽略实例来处理缺失值。 但是独立性假设对一些相互关联的属性来说可能不成立,通常的解决办法是使用贝叶斯信念网络。
具体算法详细内容见—>这里
分类器的集成
从训练数据构造一系列的分类器,并通过聚集预测值(或中间特征权重)来预测类标签。
- Bagging
- Boosting
- Stacking
评估分类器
一些常用的评估指标见—>这里
聚类分析
K-Means聚类
算法(分块方法)一开始会随机选择k个中心点,所有物品都会被分配到它们最靠近的中心节点的类中。 由于聚类新添加或移出物品,新聚类的中心节点需要更新,聚类的成员关系也需要更新。 这个操作持续下去,知道再没有物品改变它们的聚类成员关系。 算法第一次迭代时,大部分的聚类的最终位置就会发生,因此,跳出迭代的条件一般改变成“知道相对少的点改变聚类”来提高效率。
- 优点
- 简单
- 有效
- 缺点
- k值确定需要先验的数据知识
- 最终聚类对初始中心点敏感
- 可能产生空聚类
具体算法详细见—>这里
改进的K-Means聚类
DBSCAN(基于密度)通过建立密度定义作为在一定范围内的点的数量。
DBSCAN定义了三种点:
- 核心点:在给定距离内拥有超过一定数量邻居的点;
- 边界点:没有超过指定数量的邻居但属于核心点邻居;
- 噪声点:既不是核心点也不是边界点;
其他改进的聚类算法:
- 消息传递的聚类算法(基于图聚类)
- 分层聚类按照层级树的结构产生一系列嵌套聚类
注意
改进的k-means算法并没有应用于推荐算法中。k-means算法的简单和效率要优于它的替代算法。
关联规则挖掘
给定物品的频繁度称为支持量(比如(牛奶,啤酒,尿布)=131)类比频次
物品集的支持度是包含它的事务的比例(比如(牛奶,啤酒,尿布)=0.12)类比频率
关联规则挖掘的两步方法:
- 产生了所有支持度大于等于最小支持度的物品集(频繁项集生成)
- 从每一频繁物品集中产生高置信规则(规则生成)
具体可以参考Apriori算法。