递归神经网络 - GRU
GRU神经单元
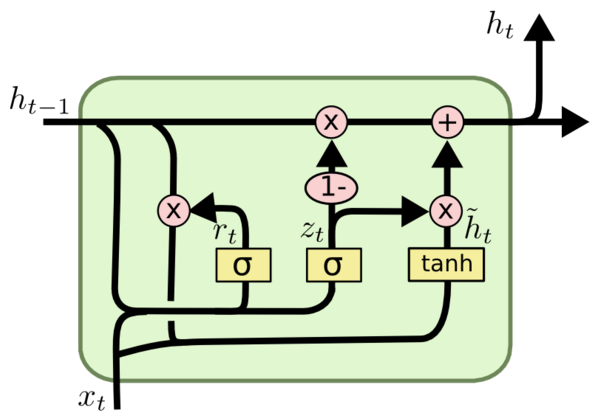
GRU神经单元与LSTM神经单元及其相似,可以二者相互对比着学习。 GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门(forget gate)和输入门(input gate)用更新门(update gate)来替代。 把cell state$C_t$和隐状态$h_t$进行合并,在计算当前时刻新信息的方法和LSTM有所不同。
重置门
更新门
更新状态
计算候选隐藏层(candidate hidden layer)$\hat{h}_t$,这个时候候选隐藏层和LSTM中的$\hat{C}_t$是类似的。 可以看成是当前时刻的新信息,其中$r_t$用来控制需要保留多少之前的记忆,如果$r_t$为$0$,那么$\hat{h}_t$只包含当前词的信息。
最后$z_t$控制需要从前一时刻的隐藏层$h_{t−1}$中遗忘多少信息,需要加入多少当前时刻的隐藏层信息$\hat{h}_t$,最后得到$h_t$,直接得到最后输出的隐藏层信息,这里与LSTM的区别是GRU中没有output gate。
如果reset gate接近0,那么之前的隐藏层信息就会丢弃,允许模型丢弃一些和未来无关的信息;
update gate控制当前时刻的隐藏层输出$h_t$需要保留多少之前的隐藏层信息,若$z_t$接近1相当于我们之前把之前的隐藏层信息拷贝到当前时刻,可以学习长距离依赖。
一般来说那些具有短距离依赖的单元reset gate比较活跃(如果$r_t$为1,而$z_t$为0那么相当于变成了一个标准的RNN,能处理短距离依赖),具有长距离依赖的单元update gate比较活跃。