K-Means聚类
1. 距离量度
1.1 两点之间的距离
- 欧式距离
- 曼哈顿距离
- 切比雪夫距离
- 余弦距离
- Jaccard相似系数
- 相关系数
1.2 两个类别之间的距离
- 单连接聚类 Single-linkage clustering
- 一个类的所有成员到另一个类的所有成员之间的最短两个之间的距离
- 全连接聚类 Complete-linkage clustering
- 两个类中最远的两个点之间的距离
- 平均连接聚类 Average-linkage clustering
- 两个类中的点两两的距离求平均
2. K-Means聚类
算法思想:
- 选择K个点作为初始质心
- repeat
- 将每个点指派到最近的质心,形成K个簇
- 重新计算每个簇的质心
- until 簇不发生变化或达到最大迭代次数
这里的重新计算每个簇的质心,如何计算是根据目标函数得来的,因此在开始时需要考虑距离度量和目标函数。
考虑欧几里得距离的数据,使用误差平方和(Sum of the Squared Error, SSE)作为聚类的目标函数,两次运行K均值产生的两个不同的簇集,我们更喜欢SSE最小的那个。
其中$K$表示$K$个聚类中心,$c_i$表示第几个中心,$dist$表示的是欧式距离。
在更新质心时使用所有点的平均值,为什么呢?这里是由SSE决定的。
对第$k$个质心$c_k$求解,最小化式(7):即对SSE求导并令导数等于零,求解$c_k$,如下:
这样,正如前面所述,簇的最小化SSE的最佳质心是簇中各点的均值。
3. K-Means算法的优缺点
- 优点
- 易实现
- 缺点
- K值需要预先给定
- 对初始选取的聚类中心点敏感
- 可能收敛到局部最小值
- 在大规模数据收敛慢
进阶学习 bisecting K-means,DBSCAN
4. 算法实现
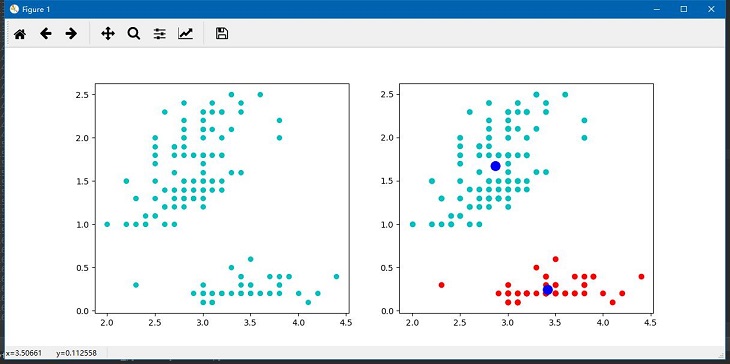
4.1 运行结果:
4.2 代码
1 | # coding:utf-8 |