My Resume (2018)
目录
- 自我介绍
- 项目1 - 基于神经网络的安卓恶意代码检测
- 项目2 - 2017开放学术精准画像大赛
- 项目3 - 微博用户画像
- 面试遇到的算法问题
- 面试遇到的数据结构问题
自我介绍
你好,我是赵卫国,目前在哈尔滨工业大学就读,计算机科学与技术专业研二,专业排名前20%, 2017年7月到10月参加了由微软、清华联合举办的《2017开放学术精准画像大赛》,我们的队伍在400多个队伍中获得了第3名的成绩; 其中我担任队长的职责,主要负责任务一和任务三的解决。
本科就读于青岛大学,网络工程专业,专业排名前10%,参加过一次蓝桥杯软件大赛,获得了山东赛区二等奖;
生活上,有自己的爱好兴趣,喜欢运动,摄影。
项目1 - 基于神经网络的安卓恶意代码检测
任务描述:
对提供的安卓应用程序,分析检测识别其中的恶意应用程序。
方法:
- 静态分析安卓应用程序,利用反编译工具获取函数调用关系图和操作码序列,使用污点分析技术获取API序列;
- 将函数调用关系图和API序列利用LSTM学习特征向量,将操作码构造成灰度图使用CNN学习特征向量;
- 使用SVM + Stacking技术进行分类。对安卓应用程序的最终分类准确率为96%。
涉及知识点
面试遇到的问题
- 1.LSTM与RNN的不同
- 2.为什么出现梯度消失和梯度爆炸
项目2 - 2017开放学术精准画像大赛
任务描述:
- Task 1:基于学者名+组织名的搜索结果,确定学者的个人主页和个人信息。
- Task 2:基于学者的论文信息,挖掘学者的研究兴趣。
- Task 3:基于学者的论文信息,预测学者截止2017年6月的论文被引用量。
方法:
- Task 1:使用搜索结果标题、URL等构造特征,样本正负比1:9,尝试过采样和负采样方法,使用XGBoost确定个人主页,CNN识别照片,朴素贝叶斯确定性别,正则表达式确定邮件等信息;
- Task 2: 基于论文题目,合著作者、论文引用关系等构造特征,使用PCA降维后训练三个分类器并将其输出结果后处理,选出学者研究兴趣;
- Task 3: 基于业务需要建立特征(h-index、论文数量等),使用XGBoost二分类后,对正例数据使用XGBoost回归预测学者论文被引用量。
涉及知识点
面试遇到的问题
- 1.SVM与LR的区别
- 2.SVM、LR、XGBoost各适用于什么场景?(数据规模、特征数量、特征特点)
- 3.手写朴素贝叶斯
项目3 - 微博用户画像
任务描述:
给定用户微博文本数据以及社交网络图,预测用户的性别(二分类)、年龄(三分类)、地域(八分类),最终采用加权准确率作为评价指标。
方法:
- 使用卡方分析提取关键词,构造BOW特征;
- 利用微博文本,使用Doc2Vec技术训练出用户的Document Vector;
- 利用社交关系,使用Graph Embedding训练用户的Node Vector作为特征;
- 综合上述特征,使用PCA降维、SVM基分类器,并采用Stacking技术进行模型融合。
- 对地域分类,额外构建了地域常识词典;对性别分类,额外建立性别倾向性词典。
- 最终准确率为性别88.3%,年龄64.8%,地域72.7%。
涉及知识点
面试遇到的问题
- 1.Word2Vec和Doc2Vec的区别联系
- 2.LINE的具体思想和目标函数
面试遇到的算法问题
- 1.生成模型和判别模型辨析
- 常见判别模型:KNN,SVM,LR
- 常见生成模型:朴素贝叶斯,隐马尔可夫模型
判别模型会生成一个表示$P(Y | X)$的判别函数(或预测模型),而生成模型先计算联合概率$P(Y,X)$,然后通过贝叶斯公式转化为条件概率。简单来说,判别模型不会计算联合概率分布,生成模型需要先计算联合概率分布。 或者理解:生成算法尝试去找到底这个数据是怎么生成的,然后再对一个信号进行分类;基于生成假设,那么哪个类别最有可能产生这个信号,这个信号就属于那个类别。 判别模型不关心数据是怎么生成的,它只关心信号之间的差别,然后用差别来简单对给定的一个信号进行分类。
- 2.LR与SVM对比
- 相同点
- 都是分类算法、监督学习算法、判别模型
- 不考虑核函数,都是线性分类算法,即它们的分类决策面都是线性的
- 不同点
- 损失函数不同。
- SVM只考虑局部的边界线附近的点(支持向量),而LR考虑全局(远离的点对分离平面起作用)
- 解决非线性问题时,SVM使用核函数机制,LR通常不采用核函数(自组合特征/Sigmoid)
- 线性SVM依赖数据表达的距离方式,需要先做normalization,LR不受其影响
- SVM自带正则,LR需要额外增加正则项
- LR可以给出每个点属于每一类的置信度(注非概率),而SVM只能分类
- 相同点
LR损失函数:
SVM损失函数:
如何选择LR和SVM
- 如果Feature的数量很大,跟样本数量差不多,这时候选用LR或者是Linear Kernel的SVM
- 如果Feature的数量比较小,样本数量一般,不算大也不算小,选用SVM + Gaussian Kernel
- 如果Feature的数量比较小,而样本数量很多,需要手工添加一些feature变成第一种情况
>
- 3.计算CNN中的感受野
公式:$ \frac{in - size}{stride} + 1 = out $
例子:经过下列卷积操作后,3×3 conv -> 3×3 conv -> 2×2 maxpool -> 3×3 conv,卷积步长为 1,没有填充,输出神经元的感受野是多大?
反向推导计算:
- conv 3x3, stride=1, out=1. $\frac{in - 3}{1} + 1 = 1 \quad \Rightarrow \quad in = 3$
- maxpool 2x2, stride=1, out=3. $ \frac{in - 2}{1} + 1 = 3 \quad \Rightarrow \quad in = 4 $
- conv 3x3, stride=1, out=4. $ \frac{in - 3}{1} + 1 = 4 \quad \Rightarrow \quad in = 6 $
- conv 3x3, stride=1, out=6. $ \frac{in - 3}{1} + 1 = 6 \quad \Rightarrow \quad in = 8 $
所以输出神经元的感受野为 8x8。
- 4.Bias和Variance的tradeoff
- A:让Error(train)尽可能小
- B:让Error(train)尽可能等于Error(test)
- 即,因为A小 and A=B,所以B小。
- 让Error(train)小 –> 模型复杂化,增加参数数量 –> low bias
- 让Error(train) == Error(test) –> 模型简单化,减少参数数量 –> low variance
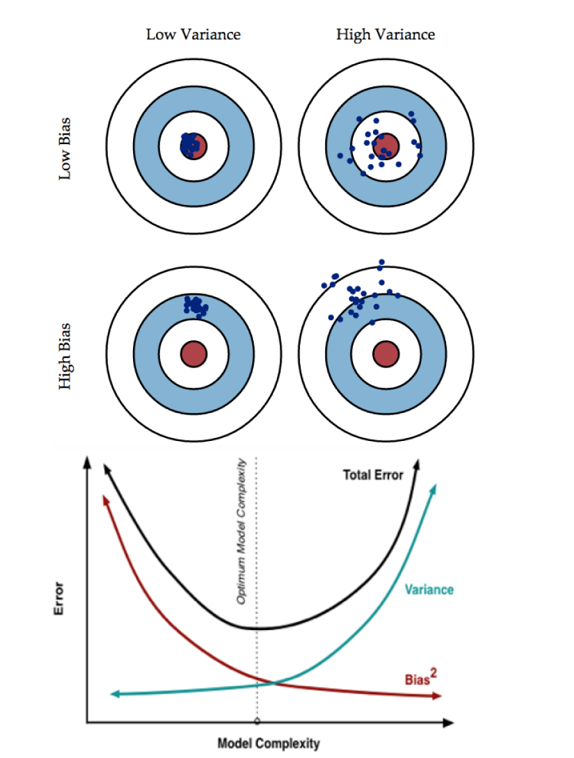
bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲就是在样本上拟合的好不好。 要想在bias上表现好(low bias),就得复杂化模型,增加模型的参数,但这样容易过拟合 (overfitting),过拟合对应上图是high variance,点很分散。 low bias对应就是点都打在靶心附近,所以瞄的是准的,但手不一定稳。
variance描述的是样本上训练出来的模型在测试集上的表现, 要想在variance上表现好(low variance),就要简化模型,减少模型的参数,但这样容易欠拟合(underfitting), 欠拟合对应上图是high bias,点偏离中心。low variance对应就是点都打的很集中,但不一定是靶心附近,手很稳,但是瞄的不准。
这个靶子上的点(hits)可以理解成一个一个的拟合模型,如果许多个拟合模型都聚集在一堆,位置比较偏,如图中(high bias, low variance)这种情景,意味着无论什么样子的数据灌进来, 拟合的模型都差不多,这个模型过于简陋了,参数太少了,复杂度太低了,这就是欠拟合; 但如果是图中(low bias, high variance)这种情景,所有拟合模型都围绕中间那个 correct target 均匀分布, 但又不够集中、很散,这就意味着,灌进来的数据一有风吹草动,拟合模型就跟着剧烈变化,这说明这个拟合模型过于复杂了、不具有普适性、泛化能力差,就是过拟合(overfitting)。
所以 bias 和 variance 的选择是一个 tradeoff , 过高的 variance 对应的概念,有点“剑走偏锋”、“矫枉过正”的意思, 如果说一个人variance比较高,可以理解为,这个人性格比较极端偏执,一条道走到黑哪怕是错的。 而过高的 bias 对应的概念,有点像“面面俱到”、“大巧若拙”的意思,如果说一个人bias比较高,可以理解为,这个人是个圆滑世故,可以照顾到每一个人,所以就比较离散。
训练一个模型的最终目的,是为了让这个模型在测试数据上拟合效果好,也就是 Error(test) 比较小,但在实际问题中 testdata 是拿不到的, 也根本不知道 testdata 的内在规律,所以我们通过什么策略来减小Error(test)呢?
- 5.神经网络中最后两个全连接层的区别
- 最后一层为logits代表分类的后验概率(对于分类问题),神经元数目为类别数目,通常连接sigmoid softmax来得到最后的后验概率;
- 普通的全连接层,神经元数目没有固定的要求,相当于用不同的模式将前层信息进行融合。
- 6.核函数与VC维之间的关系
- 7.归一化和标准化的区别
- 归一化(normalization):为了消除不同数据之间的量纲,方便数据比较和共同处理,比如在神经网络中,归一化可以加快训练网络的收敛性。
- 标准化(standardization):方便数据的下一步处理而进行的数据缩放等变换,并不是为了方便与其他数据异同处理或比较,比如数据经过零均值标准化之后,更利于使用标准正态分布的性质。
Rescaling: $ x’ = \frac{x - min(x)}{max(x) - min(x)} $
Mean Normalization: $ x’ = \frac{x - mean(x)}{max(x) - min(x)} $
Standardization: $ x’ = \frac{x - \bar{x}}{\sigma} $
Scaling to unit length: $ x’ = \frac{x}{|| x ||} $
- 8.Word2Vec
- 介绍Word2Vec
- Word2Vec的两个模型分别是CBOW和Skip-gram,两个加快训练的方法是Hierarchical Softmax和负采样;
- 假设一个训练样本是由中心词$w$和上下文$context(w)$组成,那么CBOW就是用$context(w)$去预测$w$;而Skip-gram则相反,用$w$去预测$context(w)$里的所有词。
- HS是试图用词频建立一颗哈夫曼树,那么经常出现的词路径会比较短。树的叶子节点表示词,和词典中词的数量一致,而非叶节点是模型的参数。要预测的词,转化成预测从根节点到该词所在的叶子节点的路径,是多个二分类问题。
- 对于负采样,则是把原来的Softmax多分类问题,直接转化成一个正例和多个负例的二分类问题。让正例预测1,负例预测0,这样更新局部的参数。
- 对比CBOW和Skip-gram
- 训练速度上CBOW会更快一点,因为每次会更新$context(w)$的词向量,而Skip-gram只更新中心词的词向量;
- Skip-gram对低频词效果比CBOW好,因为是尝试用当前词去预测上下文,当前词是低频高频没有区别,但CBOW类似完形填空,会倾向于选择常见或概率大的词来补全,不太会选择低频词。
- Skip-gram在大数据集上可以提取更多的信息,总体比CBOW要好一些;
- 对比HS和负采样
- 负采样更快,特别是词表比较大的时候;
- 负采样为什么要用词频来做采样频率?
- 这样可以让频率高的词先学习,然后带动其他词学习;
- 训练完有两套词向量,为什么只用其中一套?
- 对于HS来说,哈夫曼树中的参数是不能拿来做词向量的,因为没办法和词典中的词对应。
- 负采样中的参数其实可以考虑做词向量,因为中间是和前一套词向量做内积,应该是有意义的,但是考虑到负采样是基于词频的,有些词可能采不到,也就学的不好;
- 介绍Word2Vec
- 9.training set, validation set, test set的区别
- training set: 用来训练模型
- validation set:用来模型选择
- test set:用来评估所选模型的实际性能
- 10.LSTM的公式
- 遗忘门:$ ft = \sigma ( W_f x_t + U_f h{t-1} + b_f ) $
- 输入门:$ it = \sigma ( W_i x_t + U_i h{t-1} + b_i ) $
- 输出门:$ ot = \sigma ( W_o x_t + U_o h{t-1} + b_o ) $
- 神经元状态:$ ct = f_t \circ c{t-1} + it \circ \tanh ( W_c x_t + U_c h{t-1} + b_c ) $
- 输出值:$ h_t = o_t \circ \sigma ( c_t ) $
- LSTM详细内容
- 11.GBDT、随机森林、XGBoost的区别
- 随机森林
- 容易理解和解释,树可以被可视化
- 不需要进行数据归一化
- 不容易过拟合
- 自带out-of-bag (oob)错误评估功能
- 易于并行化
- 不适合小样本,只适合大样本
- 树之间的相关性越大,整体错误率越高
- 单棵树的错误率越高,整体错误率越高
- 基树可以是分类树,也可以是回归树
- 能够处理很高维的数据,并且不用特征选择,而且在训练完后,给出特征的重要性
- GBDT
- 基树只能是回归树,因为要拟合残差
- 灵活的处理各种类型的数据
- 基树的关系,只能串行
- 缺失值敏感
- XGBoost
- 不仅支持回归树,还支持线性分类器
- GBDT用到一阶导数,XGB用到二阶导数
- 代价函数中有正则项(叶结点数量+叶结点输出值的平方)
- 列抽样
- 缺失值不敏感,可以自学习分裂方向
- 部分并行
- 随机森林
- 12.数据之间如果不是独立同分布的会怎样
- 独立同分布是为了合理用于测试集,可解释
- 统计机器学习的假设就是数据独立同分布
- 13.神经网络里面的损失函数
- Softmax Cross Entropy Loss
- $ E(y, \hat{y} ) = - \sum_j y_j log \hat{y}_j $
- 其中$y$表示神经网络的目标标签,$\hat{y}$表示神经网络的输出值。
- $\hat{y}$表示softmax损失函数
- $ \hat{y}_j = softmax(z_j) = e^{z_j} / \sum_j e^{z_j} $
- Mean Square Loss
- $ mse = \frac{1}{n} \sum_{i=1}^n (\hat{y}_i - y_i)^2 $
- Softmax Cross Entropy Loss
- 14.常见的激活函数及导数
- 指数
- $ y = exp(h) $
- $ y’ = exp(h) $
- sigmoid
- $ y = \frac{1}{1+e^{-h}} $
- $ y’ = y \times (1-y) $
- tanh
- $ y = tanh(h) = \frac{e^h - e^{-h}}{e^h + e^{-h}} $
- $ y’ = 1- h^2 $
- 零均值的解释
- Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in ),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
- 指数
- 15.bagging减小方差,boosting减小偏差 来源
- Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均
- Boostring是增量学习算法,每次学习前向的偏差(梯度),将多个模型的结果相加
- bagging由于$ E[\sum X_i / n] = E[X_i] $,所以bagging后的bias和单个子模型的bias接近,不能减小bias
- bagging由于$ Var[\sum X_i / n] = Var(X_i) / n $,所以可以显著降低variance
- boostring是在迭代最小化损失函数,其bias自然逐步下降。但是各子模型之间是强相关的,故子模型之和不能降低variance
- 16.深度学习中,L2和dropout的区别
- L2通过控制参数的值,而不修改模型
- dropout直接减少训练参数的数量,将大模型分割成多个小模型
- 机器学习算法使用场景
- CRF分词、语法依存分析、命名实体识别,但是现在正在越来越多的应用场景里被 RNN 以及它的变种们所替代,LSTM+CRF的解决方案取得了state of art的效果
- LR做CTR预估,商品推荐转换为点击率预估也可以用该模型。着重了解推导,正则化及并行,但现在越来越多的依赖于深度学习,包括DNN,DRL
- SVM可以做文本分类,人脸识别等,了解下原始问题如何转换为对偶问题,然后使用SMO求解,还有了解下核函数
- adaboost 本身是exp loss在boosting方法下的模型
- EM 是一种优化算法,本质个人认为有点类似于离散空间的梯度上升算法,一般是结合具体的算法来用,比如混合高斯模型,最大熵,无监督HMM等,但比较经典的还是pLSA,k-means背后也有em的思想
- 决策树可以认为是将空间进行划分,ID3和C4.5算是比较经典的决策树算法,可以用来分类,也可以用来回归,但业界很少直接使用一棵树,一般使用多棵树,组成committee,较为经典有GBDT 和RF,两者都是ensemble learning的典范,只不过前者使用boosting降低bias,后者使用bagging降低variance从而提升模型的performance。在ESL中有个对比,使树形模型几乎完爆其他算法,泛化能力和学习能力都很牛逼。业界的话一般用来做搜索排序和相关性。
- HMM在基础的一阶马尔可夫的基础之上,加入隐含状态,有两者假设,解决三种问题,一般时间序列预测都可以用该模型,当然了,NLP中的分词,语音识别等效果也还不错
面试遇到的数据结构问题
- 1.链表判断是否有环及环的入口节点
先用一快一慢指针,当慢指针追上快指针时-有环;当快指针指向空时-没有环;之后,统计环的长度,快指针和慢指针相等时,慢指针停下,快指针接着走,再次相等时可以得到环的长度K; 重新从起始点开始,快指针比慢指针多走K步,二者相等时所指的节点为环的入口节点;
2.快速排序、二分查找
3.TopK问题
面试遇到的实践题
1.往模型中加入一个特征,如何判定这个特征是否有效
2.逻辑回归的所有样本的都是正样本,那么学出来的超平面是怎样的?
- 所有数据点分布在超平面的一侧