Doc2Vec Tutorial
目录
- gensim简单使用
- Doc2Vec(PV-DM)
- Doc2Vec(PV-DBOW)
gensim简单使用
模型参数说明:
- dm=1 PV-DM dm=0 PV-DBOW。
- size 所得向量的维度。
- window 上下文词语离当前词语的最大距离。
- alpha 初始学习率,在训练中会下降到min_alpha。
- min_count 词频小于min_count的词会被忽略。
- max_vocab_size 最大词汇表size,每一百万词会需要1GB的内存,默认没有限制。
- sample 下采样比例。
- iter 在整个语料上的迭代次数(epochs),推荐10到20。
- hs=1 hierarchical softmax ,hs=0(default) negative sampling。
- dm_mean=0(default) 上下文向量取综合,dm_mean=1 上下文向量取均值。
- dbow_words:1训练词向量,0只训练doc向量。
1 | # coding: utf-8 |
需要说明的一点是这里的Paragraph Vector不是真的段落向量的意思,它可以根据需要的不同进行变化,可以是短语、句子甚至是文档。
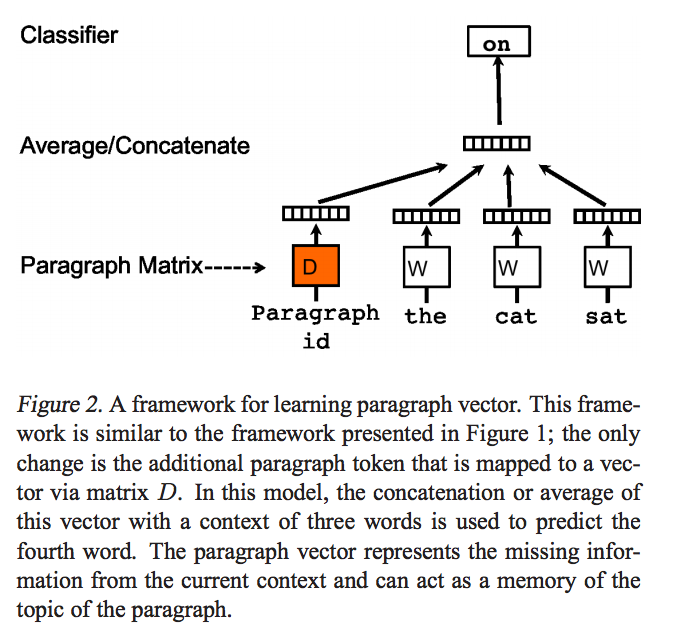
Doc2Vec(PV-DM)
PV-DM在模型的输入层新增了一个Paragraph id,用于表征输入上下文所在的Paragraph。 例如如果需要训练得到句子向量,那么Paragraph id即为语料库中的每个句子的表示。 Paragraph id其实也是一个向量,具有和词向量一样的维度,但是它们来自不同的向量空间,D和W,也就是来自于两个不同的矩阵。 剩下的思路和CBOW模型基本一样。在模型中值得注意的一点是,在同一个Paragraph中,进行窗口滑动时,Paragraph id是不变的。
Paragraph id本质上就是一个word,只是这个word唯一代表了这个paragraph,丰富了context vector。
- 模型的具体步骤如下:
- 每个段落都映射到一个唯一的向量,由矩阵$D$中的一列表示,每个词也被映射到一个唯一的向量,表示为$W$ ;
- 对当前段落向量和当前上下文所有词向量一起进行取平均值或连接操作,生成的向量用于输入到softmax层,以预测上下文中的下一个词:
- 这个段落向量可以被认为是另一个词。可以将它理解为一种记忆单元,记住当前上下文所缺失的内容或段落的主题 ;
- 矩阵$D$ 和$W$ 的区别:
- 通过当前段落的index,对$D$ 进行Lookup得到的段落向量,对于当前段落的所有上下文是共享的,但是其他段落的上下文并不会影响它的值,也就是说它不会跨段落(not across paragraphs) ;
- 当时词向量矩阵$W$对于所有段落、所有上下文都是共享的。
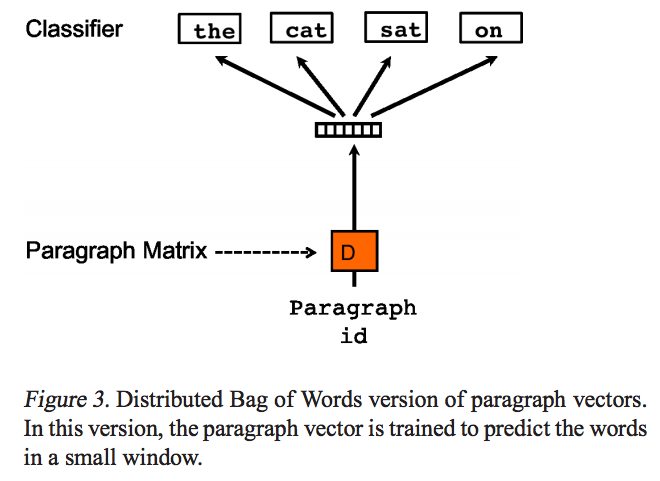
Doc2Vec(PV-DBOW)
模型希望通过输入一个Paragraph id来预测该Paragraph中的单词的概率,和Skip-gram模型非常的类似。
- PV-DBOW模型的输入忽略了的上下文单词,但是关注模型从输出的段落中预测从段落中随机抽取的单词;
- PV-DBOW模型和训练词向量的Skip-gram模型非常相似。
Doc2Vec的特点
- 可以从未标记的数据中学习,在没有足够多带标记的数据上仍工作良好;
- 继承了词向量的词的语义(semantics)的特点;
- 会考虑词的顺序(至少在某个小上下文中会考虑)