递归神经网络RNN初识 - LSTM
目录
- 1.循环神经网络
- 2.长期依赖的问题
- 3.LSTM 网络
- 4.LSTM的变种
- 5.结论
译自:Understanding LSTM Networks
1.循环神经网络
人类不会每秒钟都从头开始思考。在阅读本文时,你可以根据以前单词的理解来理解每个单词。你不要把所有东西都扔掉,再从头开始思考。 你的想法有持久性。 在这方面,传统神经网络不能做到这一点,这是一个很大的缺点。 例如,想象一下,当你想要分析电影中剧情的发展。 传统神经网络是不能够利用电影中以前的事件来推理以后的事情的。 而循环神经网络解决了这个问题。 它们是具有循环的网络,允许信息影响持续存在。
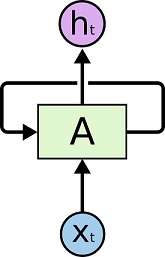
在上图中,一组神经网络$A$输入$X_t$并输出一个值$h_t$。 循环允许信息从网络的一个步骤传递到下一个。 这些循环使得循环神经网络显得很神秘。 然而,如果你仔细想想,它们并不与一般的神经网络完全不同。 一个循环神经网络可以被认为是同一个网络的多个副本,每一个都传递一个信息给后继者。 考虑如果我们展开循环会发生什么:
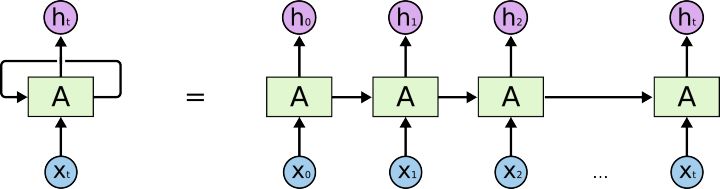
这种链状特征揭示了循环神经网络与序列和列表密切相关,它们是用于此类数据的神经网络的自然结构。 而且他们确实得到应用! 在过去几年里,将RNN应用于语音识别,语言建模,翻译,图像字幕等各种问题已经取得了令人难以置信的成功。 我将讨论可以通过RNN实现的令人惊叹的专长,使Andrej Karpathy的优秀博客 “The Unreasonable Effectiveness of Recurrent Neural Networks”成为可能。 但他们真的很神奇。这些成功的关键在于使用“LSTM”,这是一种非常特殊的循环神经网络,对于许多任务来说,它们比标准版本好得多。 几乎所有令人兴奋的结果基于循环神经网络是通过他们实现的。这篇文章将探讨这些LSTM。
2.长期依赖的问题
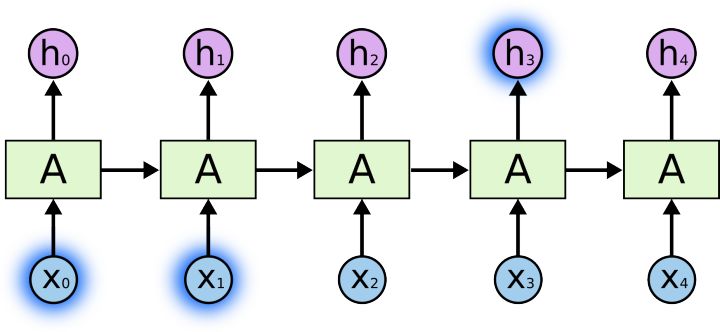
RNNs吸引人的一点在于它能够将过去的信息连接到当前任务,例如使用先前的视频帧可以为当前帧的理解提供信息。如果RNNs可以做到这一点,他们将非常有用。 但他们可以吗?这取决于不同的情况。有时候,我们只需要最近的信息来处理当前的任务。 举个例子,输入法能够通过你输入的上一个词来预测你想要输入的下一个词。比如,我们想要预测“云彩在天上”,我们不需要更多的信息就能够预测最后两个字。 在这种情况下,如果相关信息与所需预测的信息间隔很小,则RNN可以学习使用过去的信息。
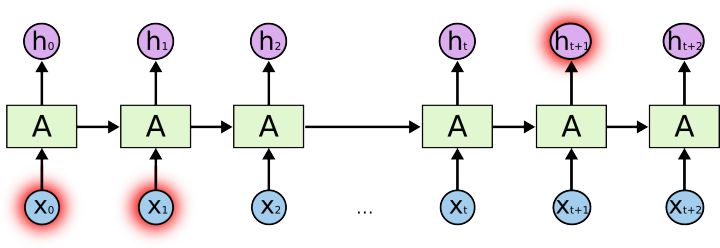
但有些情况下我们就需要更多的文本。比如预测“我来自法国…我法语很流利…”,最近的信息预测这是一个语言名词,但是当我们想确定具体是哪一种语言的时候, 我们需要找到包含法国的文本,但这个文本很可能间隔非常远。很不幸,当间隔增加,RNNs就会更难以连接相关的信息。
理论上,RNNs完全有能力有能力处理这样的“长期依赖”。一个人可以仔细挑选参数来解决这种形式的问题。但实践却表明RNNs似乎不能学习。 Hochreiter(1991) German深层次的揭露了这个问题, 而Bengio,et al.(1994)解释了一些基本的原因。
但是,LSTMs没有这个问题!
3.LSTM 网络
长短记忆网络(Long Short Term Memory networks)通常称为“LSTMs”-是一种特殊的RNN,有能力学习长期的依赖。 LSTMs最初由Hochreiter & Schmidhuber (1997)提出, 并在之后的工作中由许多人优化推广。LSTM在各种各样的问题上工作得很好,现在被广泛使用。
LSTM专为解决长期依赖问题而设计。记忆长周期的信息是默认的行为而不是努力需要学习的东西。 现有的循环神经网络都会有一个链来重复神经网络的模块。在标准的RNN中一般是一个非常简单的结构,如一个$tanh$层。
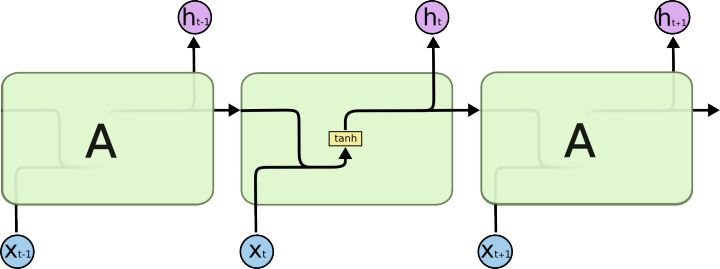
LSTMs也有一个类似链结构,但是重复模块有一个复杂的结构。相对于单神经网络层,LSTM有4层,以一个非常特殊的方式交互。
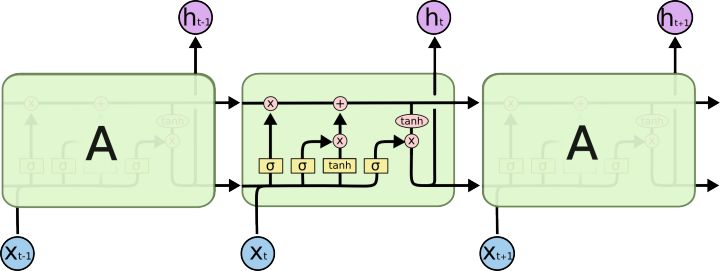
不用担心其中的细节。我们将会一步步图解LSTM。现在让我们熟悉一下将用到的符号。

在上图中,每个线代表一个完整的向量,从一个节点输出到其他节点的输入,粉色的圈代表节点操作, 比如向量加,而黄色框是学习到的神经网络层。线合并代表连接,线分叉代表复制。
LSTMs背后的核心概念
LSTM的关键是Cell的状态,水平线穿过计算图的顶部。Cell状态有点像输送带。直接在整个链上运行,只有一些小的线性相互作用。 信息流畅地保持不变。
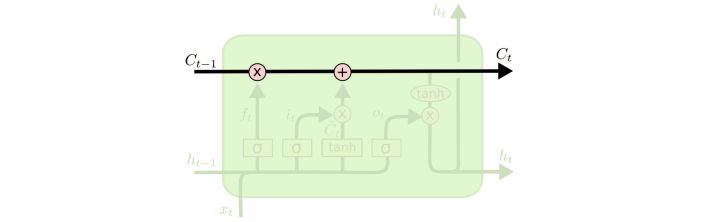
LSTMs没有能力去添加或者删除cell状态的信息,而是由称作门(gates)的结构进行调节。 门是一个可以让信息选择性通过的结构。由一个$sigmoid$神经网络层和一个节点乘算法组成。
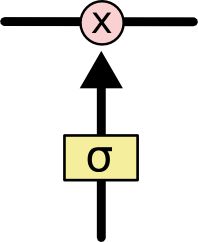
一步步了解LSTM
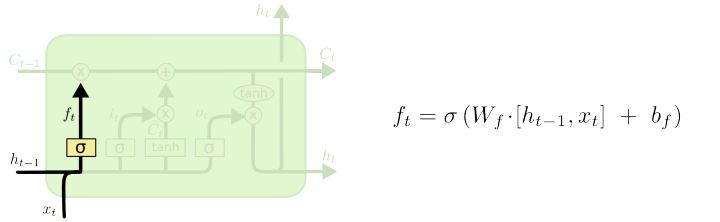
LSTM中,第一步是决定我们将丢弃什么信息,并把剩下的送入cell状态。这个决定由叫做遗忘门层(forget gate layer)的$sigmoid$层做出。 它通过观察$h{t-1}$和$x_t$,为cell状态$C{t-1}$中的每个数输出一个 0 到 1 之间的数,1表示完全保留,0表示完全抛弃。
让我们回到语言模型的例子。在这个预测下一个单词的问题中,cell状态也许会包含前面对象的属性,所以可以使用正确的代名词。当我们看到一个新的对象,我们希望忘记旧对象的属性。
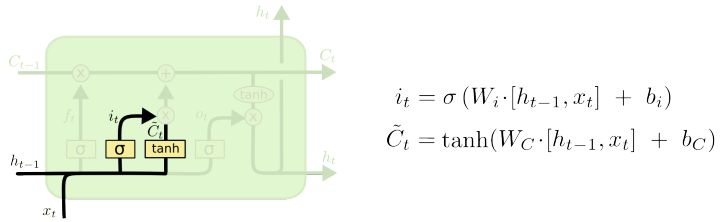
下一步是来决定我们将保存什么新信息到cell状态中。这有两个部分: 首先,一个$sigmoid$层(input gate layer, 输入门层)决定哪个值将被更新; 然后,一个$tanh$层创建一个新候选值的向量$ \tilde{C}_t $,可以被加入到cell状态中。在下一步,我们将要合并这两步来创建一个状态的更新。
在语言模型的例子里,我们想要添加新对象的属性到cell状态中来替换我们希望遗忘的旧对象的属性。
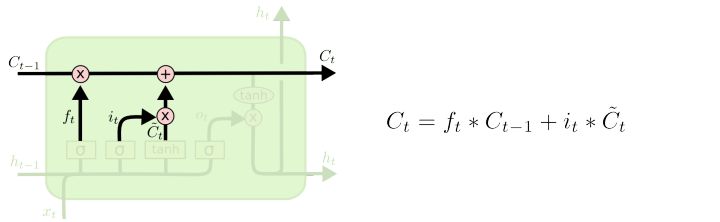
现在是时候来更新旧的cell状态$C_{t-1}$为新状态$C_t$。前面的步骤已经决定了应该做什么,我们只需要实施。
我们将旧状态乘$f_t$,忘记我们之前决定忘记的东西。然后我们加上$i_t * \tilde{C}_t$。这是新的候选值,由我们决定更新每一个状态值的多少来缩放。
在语言模型的例子里,这是我们丢弃旧对象信息并添加新信息的地方。就如同我们在前一步决定的那样。
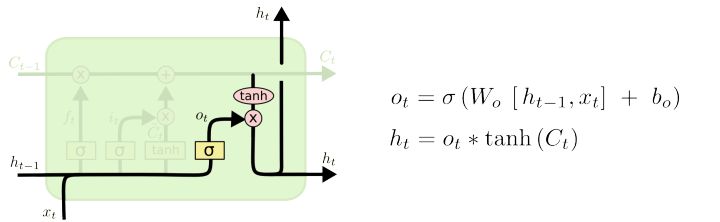
最终,我们需要决定输出什么(output gate layer,输出门层)。这输出将基于我们的cell状态,但会是一个过滤(filtered)后的版本。 首先,我们运行一个$sigmoid$层来决定cell状态的哪些部分将被输出。然后,我们将cell状态通过$tanh$(将值转化为-1到1之间)并与$sigmoid$门的输出相乘,就可以只输出我们想要的部分。
对于语言模型例子,因为只看到一个对象,在预测下一个词的时候,它也许想要输出一个关于动词的信息。 比如,它也许输出这个对象是单数还是复数,因此我们知道接下来的是一个动词形式的。
4.LSTM的变种
上文讲述了一个普通的LSTM。但不是所有的LSTMs都和上面一样。事实上,看起来几乎所有论文都用了一个有一点不一样的LSTM。区别很小,但是值得注意。
一个著名的LSTM变种,由Gers & Schmidhuber (2000)提出, 添加了窥视孔连接(peephole connections)。这意味着可以让门层查看cell状态(This means that we let the gate layers look at the cell state)。
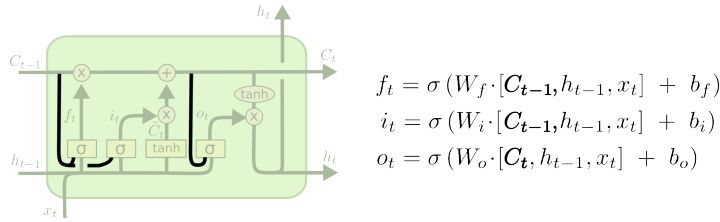
上面的图添加了链接到所有门的窥孔,但很多论文只会添加其中的一些。
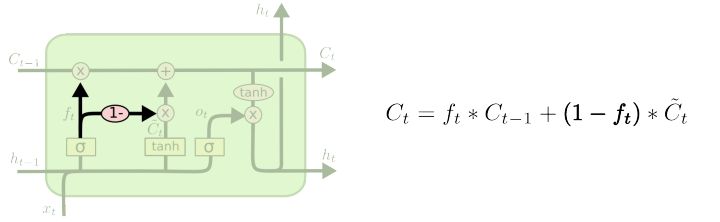
另一个变种是使用耦合的遗忘和输出门。相对于普通的LSTM分别决定添加和遗忘什么信息,这个变种同时作出决定,只在输入相同位置信息的时候遗忘当前的信息。 只有在忘记一些值的时候才输入新值到状态中。
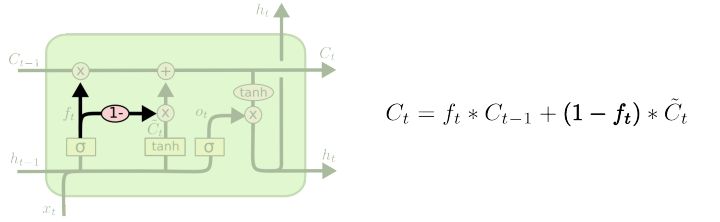
一个有点戏剧化的LSTM变种是GRU(Gated Recurrent Unit),由 Cho, et al. (2014)介绍。 它把遗忘和输入门结合成一个“更新门”,同时还合并了cell状态和隐藏状态,并有其他一些改变。这使得模型比标准LSTM要简洁,并越来越流行。
这只是众多值得注意的LSTM变种中的几个。还有很多,如Depth Gated RNNs,Yao, et al. (2015)。 同时还有一些完全不同的追踪长依赖的方式,比如Clockwork RNNs,Koutnik, et al. (2014).
哪个变种是最好的?差别有必要吗?Greff, et al. (2015)对流行的变种做了一个总结,发现他们几乎一样。 Jozefowicz, et al. (2015)测试了超过一万种RNN结构,发现有一些在特定问题上比LSTM更好。
5.结论
早前提到了人们在RNN获得的显著成就。基本都是由LSTM实现的,他们对于大多数任务都工作的很好!
LSTM的方程看起来很吓人,但是通过本文一步一步讲解,希望它们看起来更易懂。
LSTM是我们可以用RNN完成的一大进步。很自然的,我们会想,还有另一大步吗?研究人员的共同观点是:是的! 还有下一步这就是注意力(attention)!这个想法是让RNN的每一步从一些较大的信息合集中挑选信息。 比如,您使用RNN创建描述图像的标题,则可能会选择图像的一部分来查看其输出的每个字。 事实上Xu, et al. (2015)做了这个,如果你想要探索更多关于注意力,这可能是一个有趣的起点! 有一些真正令人兴奋的结果使用了注意力…
注意力并不是RNN研究中唯一的突破口。例如Grid LSTMs,Kalchbrenner, et al. (2015)看起来非常有意思。 在生成模型中使用 RNN 进行工作,如Gregor, et al. (2015), Chung, et al. (2015), Bayer & Osendorfer (2015)。