反向传播 BP & BPTT
目录
- 反向传播BP
- 随时间反向传播BPTT
1. 反向传播BP
[Calculus on Computational Graphs: Backpropagation,英文原版]、 [详解反向传播算法,中文翻译理解]
解释了为什么从上而下计算梯度。一言以蔽之:从下而上会有重复计算,当参数数量太多,时间耗费太严重;从上而下每个节点只计算一次。
如何直观地解释 back propagation 算法?中的例子比较清晰的刻画了反向传播的优势。
A Neural Network in 11 lines of Python每行代码都有解释。
CHAPTER 2How the backpropagation algorithm works讲的特别详细, 中文版在这里 - 神经⽹络与深度学习。
以下部分参考Neural Networks and Deep Learning(神经⽹络与深度学习P37 - P42)
反向传播的四个方程式:
\[ \delta^L = \nabla _a C \odot \sigma’ (z^L) \tag{BP1} \]
\[ \delta^l = ( (w^{l+1})^T \delta^{l+1} ) \odot \sigma’ (z^l) \tag{BP2} \]
\[ \frac{\partial C}{\partial b_j^l} = \delta_j^l \tag{BP3} \]
\[ \frac{\partial C}{\partial w_{jk}^l} = a_k^{l-1} \delta_j^l \tag{BP4} \]
证明上面的四个方程式:
证明BP1
\[ \begin{equation} \begin{aligned} \delta_j^L & = \frac{\partial C}{\partial z_j^L} \\ & = \frac{\partial C}{\partial a_j^L} \cdot \frac{\partial a_j^L}{\partial z_j^L} \\ & = \frac{\partial C}{\partial a_j^L} \cdot \sigma’ (z_j^L) \quad (\because a_j^L = \sigma (z_j^L)) \end{aligned} \end{equation} \]
证明BP2
\[ \begin{equation} \begin{aligned} \delta_j^l & = \frac{\partial C}{\partial z_j^l} \\ & = \sum_k \frac{\partial C}{\partial z_k^{l+1}} \cdot \frac{\partial z_k^{l+1}}{\partial z_j^l} \\ & = \sum_k \frac{\partial z_k^{l+1}}{\partial z_k^l} \cdot \delta_k^{l+1} \\ & = \sum_k w_{kj}^{l+1} \cdot \sigma’ (z_j^l) \cdot \delta_k^{l+1} \\ & = \sum_k w_{kj}^{l+1} \cdot \delta_k^{l+1} \cdot \sigma’ (z_j^l) \end{aligned} \end{equation} \]
证明BP3
\[ \begin{equation} \begin{aligned} \frac{\partial C}{\partial b_j^l} & = \frac{\partial C}{\partial z_j^l} \cdot \frac{\partial z_j^l}{\partial b_j^l} \\ & = \frac{\partial C}{\partial z_j^l} \quad (\because z_j^l = \sum_k w_{jk}^l \cdot a_k^{l-1} + b_j^l \therefore \frac{\partial z_j^l}{\partial b_j^l} = 1) \\ & = \delta_j^l \end{aligned} \end{equation} \]
证明BP4
\[ \begin{equation} \begin{aligned} \frac{\partial C}{\partial w_{jk}^l} & = \frac{\partial C}{\partial z_j^l} \cdot \frac{\partial z_j^l}{\partial w_{jk}^l} \\ & = \delta_j^l \cdot a_k^{l-1} \quad (\because z_j^l = \sum_k w_{jk}^l \cdot a_k^{l-1} + b_j^l) \end{aligned} \end{equation} \]
以下摘抄自:反向传导算法
反向传播算法的思路如下:给定一个样例 \( (x,y) \),首先进行“前向传导”运算,计算出网络中所有的激活值,包括 \( h_{W,b}(x) \) 的输出值。 之后,针对第 \( l \) 层的每一个节点 \( i \),计算出其 “残差” \( \delta^{(l)}_i \),该残差表明了该节点对最终输出值的残差产生了多少影响。 对于最终的输出节点,可以直接算出网络产生的激活值与实际值之间的差距,将这个差距定义为 \( \delta^{(n_l)}_i \)(第 \( n_l \) 层表示输出层)。 对于隐藏单元如何处理呢?基于节点(第 \( l+1 \) 层节点)残差的加权平均值计算 \( \delta^{(l)}_i \),这些节点以 \( a^{(l)}_i \) 作为输入。 下面将给出反向传导算法的细节:
- (1) 进行前馈传导计算,利用前向传导公式,得到 \( L_2, L_3, \ldots \) 直到输出层 \( L_{n_l} \) 的激活值。
- (2) 对于第 \( n_l \) 层(输出层)的每个输出单元 \( i \) ,根据以下公式计算残差: \[ \delta^{(n_l)}_i = \frac{\partial}{\partial z^{(n_l)}_i} \frac{1}{2} || y - h_{W,b}(x) || ^2 = - (y_i - a^{(n_l)}_i) \cdot f’(z^{(n_l)}_i) \]
推导过程
\[ \begin{equation} \begin{aligned} \delta^{(n_l)}_i & = \frac{\partial}{\partial z^{(n_l)}_i} J(W,b; x,y) \\ & = \frac{\partial}{\partial z^{(n_l)}_i} \frac{1}{2} ||y - h_{W,b}(x) ||^2 \\ & = \frac{\partial}{\partial z^{(n_l)}_i} \frac{1}{2} \sum_{j=1}^{S_{n_l}} (y_j - a_j^{(n_l)})^2 \\ & = \frac{\partial}{\partial z^{(n_l)}_i} \frac{1}{2} \sum_{j=1}^{S_{n_l}} (y_j - f(z_j^{(n_l)}))^2 \\ & = - (y_i - f(z_i^{(n_l)})) \cdot f’(z^{(n_l)}_i) \\ & = - (y_i - a^{(n_l)}_i) \cdot f’(z^{(n_l)}_i) \end{aligned} \end{equation} \]
- (3) 对 $ l = n_l - 1, n_l-2, n_l-3, \ldots, 2 $ 的各个层,第 $ l $ 层的第 $i$ 个节点的残差计算方法如下: \[ \delta^{(l)}_i = \left( \sum_{j=1}^{s_{l+1}} W^{(l)}_{ji} \delta^{(l+1)}_j \right) f’(z^{(l)}_i) \]
推导过程
将上式中的 \( n_l-1 \) 与 \( n_l \) 的关系替换为 \( l \) 与 \( l+1 \) 的关系,就可以得到:
以上逐次从后向前求导的过程即为“反向传导”的本意所在。
- (4) 计算需要的偏导数,计算方法如下: \[ \begin{aligned} \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x, y) &= a^{(l)}_j \delta_i^{(l+1)} \\ \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x, y) &= \delta_i^{(l+1)}. \end{aligned} \]
最后,用矩阵-向量表示法重写以上算法。我们使用 “ \( \bullet \)” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。 若 \( a = b \bullet c \),则 \( a_i = b_i c_i \)。扩展 \( f(\cdot) \) 的定义,使其包含向量运算,于是有 \( f’([z_1, z_2, z_3]) = [f’(z_1), f’(z_2), f’(z_3)] \)。
那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到 \( L_2, L_3, \ldots \) 直到输出层 \( L_{n_l} \) 的激活值。
- 对输出层(第 \( n_l \) 层),计算:\[\begin{align} \delta^{(n_l)} = - (y - a^{(n_l)}) \bullet f’(z^{(n_l)}) \end{align}\]
- 对于 \( l = n_l-1, n_l-2, n_l-3, \ldots, 2 \) 的各层,计算:\[\begin{align} \delta^{(l)} = \left((W^{(l)})^T \delta^{(l+1)}\right) \bullet f’(z^{(l)}) \end{align} \]
- 计算最终需要的偏导数值:
实现中应注意:
在以上的第2步和第3步中,我们需要为每一个 \( i \) 值计算其 \( f’(z^{(l)}_i) \) 。 假设 \( f(z) \) 是sigmoid函数,并且我们已经在前向传导运算中得到了 \( a^{(l)}_i \) 。 那么,使用我们早先推导出的 \( f’(z) \) 表达式,就可以计算得到 \( f’(z^{(l)}_i) = a^{(l)}_i (1- a^{(l)}_i) \)。
最后,我们将对梯度下降算法做个全面总结。在下面的伪代码中,\( \Delta W^{(l)} \) 是一个与矩阵 \( W^{(l)} \) 维度相同的矩阵, \( \Delta b^{(l)} \) 是一个与 \( b^{(l)} \) 维度相同的向量。 注意这里 “\( \Delta W^{(l)} \) ”是一个矩阵,而不是“\( \Delta \) 与 \( W^{(l)} \) 相乘”。
下面,我们实现批量梯度下降法中的一次迭代:
- (1) 对于所有 \( l \),令 \( \Delta W^{(l)} := 0, \Delta b^{(l)} := 0 \) (设置为全零矩阵或全零向量)
- (2) 对于 \( i = 1 \) 到 \( m \),
- (2.1) 使用反向传播算法计算 \( \nabla_{W^{(l)}} J(W,b;x,y) \) 和 \( \nabla_{b^{(l)}} J(W,b;x,y) \);
- (2.2) 计算 \( \Delta W^{(l)} := \Delta W^{(l)} + \nabla_{W^{(l)}} J(W,b;x,y) \);
- (2.3) 计算 \( \Delta b^{(l)} := \Delta b^{(l)} + \nabla_{b^{(l)}} J(W,b;x,y) \);
- (3) 更新权重参数: \[ \begin{align} W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\ b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right] \end{align} \]
现在,可以重复梯度下降法的迭代步骤来减小代价函数 \( J(W,b) \) 的值,进而求解我们的神经网络。
2. [转]随时间反向传播BPTT
转自:hschen0712/machine-learning-notes
RNN(递归神经网络,Recurrent Neural Network)是一种具有长时记忆能力的神经网络模型,被广泛应用于序列标注(Sequence Labeling)问题。 在序列标注问题中,模型的输入是一段时间序列,记为$ x = \lbrace x_1, x_2, …, x_T \rbrace $, 我们的目标是为输入序列的每个元素打上标签集合中的对应标签,记为$ y = \lbrace y_1, y_2, …, y_T \rbrace $。
NLP中的大部分任务(比如分词、实体识别、词性标注)都可以最终归结为序列标注问题。 这类问题中,输入是语料库中一段由 $T$ 个词(或字)构成的文本 $ x = \lbrace x_1, x_2, …, x_T \rbrace $(其中$x_t$表示文本中的第$t$个词); 输出是每个词对应的标签,根据任务的不同标签的形式也各不相同,但本质上都是针对每个词根据它的上下文进行标签的分类。
一个典型的RNN的结构如下图所示:
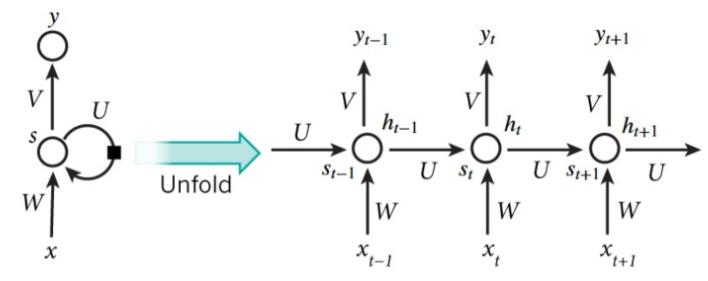
从图中可以看到,一个RNN通常由三层组成,分别是输入层、隐藏层和输出层。 与一般的神经网络不同的地方是,RNN的隐藏层存在一条有向反馈边,正是这种反馈机制赋予了RNN记忆能力。 要理解左边的图可能有点难度,我们可以将其展开为右边这种更直观的形式,其中RNN的每个神经元接受当前时刻的输入$x_t$ 以及上一时刻隐单元的输出$h_{t-1}$, 计算出当前神经元的输入 $s_t$,经过激活函数变换得到输出 $h_t$,并传递给下一时刻的隐单元。 此外,我们还需要注意到RNN中每个时刻上的神经元的参数都是相同的(类似CNN的权值共享),这么做一方面是减小参数空间,保证泛化能力; 另一方面是为了赋予RNN记忆能力,将有用信息存储在$W_{in},W_{rec},W_{out}$三个矩阵中。
由于RNN是一种基于时序数据的神经网络模型,因此传统的BP算法并不适用于该模型的优化,这要求我们提出新的优化算法。 RNN中最常用的优化算法是随时间反向传播(BackPropagation Through Time,BPTT),下文将叙述BPTT算法的数学推导。
2.1 符号注解
| 符号 | 注解 |
|---|---|
| $K$ | 词汇表的大小 |
| $T$ | 句子的长度 |
| $H$ | 隐藏层单元数 |
| $x=\lbrace x_1, x_2, ..., x_T \rbrace $ | 句子的单词序列 |
| $x_t \in R^{K \times 1}$ | 第$t$时刻RNN的输入,one-hot vector |
| $\hat{y}_t \in R^{K \times 1} $ | 第$t$时刻softmax层的输出,估计每个词出现的概率 |
| $y_t \in R^{K \times 1} $ | 第$t$时刻的label,为每个词出现的概率,one-hot vector |
| $E_t$ | 第$t$时刻(第$t$个word)的损失函数,定义为交叉熵误差$E_t = - y_t^T log (\hat{y}_t) $ |
| $E$ | 一个句子的损失函数,由各个时刻(即每个word)的损失函数组成,$E=\sum_t^T E_t$(注:由于要推导的是SGD算法,更新梯度是相对于一个训练样例而言的,因此一次只考虑一个句子的误差,而不是整个训练集的误差(对应BGD算法)) |
| $s_t \in R^{H \times 1}$ | 第$t$个时刻RNN隐藏层的输入 |
| $h_t \in R^{H \times 1}$ | 第$t$个时刻RNN隐藏层的输出 |
| $z_t \in R^{K \times 1}$ | 输出层的汇集输入 |
| $\delta^{(t)}_k=\frac{\partial E_t}{\partial s_k}$ | 第$t$个时刻损失函数$E_t$对第$k$时刻带权输入$s_k$的导数 |
| $r_t=\hat{y}_t-y_t$ | 残差向量 |
| $W_{in}\in\mathbb{R}^{H\times K}$ | 从输入层到隐藏层的权值 |
| $W_{rec}\in\mathbb{R}^{H\times H}$ | 隐藏层上一个时刻到当前时刻的权值 |
| $W_{out}\in\mathbb{R}^{K\times H}$ | 隐藏层到输出层的权值 |
上述符号之间的关系:
这里有必要对上面的一些符号进行进一步解释。
- 本文只讨论输入为one-hot vector的情况,这种向量的特点是茫茫0海中的一个1,即只用一个1表示某个单词的出现;其余的0均表示单词不出现。
- RNN要预测的输出是一个one-hot vector,表示下一个时刻各个单词出现的概率。
- 由于$y_t$是one-hot vector,不妨假设$y_{t,j} = 1( y_{t,i} =0 ,i \neq j)$,那么当前时刻的交叉熵为 。也就是说如果 $t$ 出现的是第 $j$ 个词,那么计算交叉熵时候只要看 $\hat{y}_t$ 的第$j$个分量即可。
- 由于$x_t$是one-hot向量,假设第$j$个词出现,则$W_{in}x_t$相当于把$W_{in}$的第$j$列选出来,因此这一步是不用进行任何矩阵运算的,直接做下标操作即可。
BPTT与BP类似,是在时间上反传的梯度下降算法。 RNN中,我们的目的是求得 $\frac{\partial E}{\partial W_{in}}, \frac{\partial E}{\partial W_{rec}}, \frac{\partial E}{\partial W_{out}}$, 根据这三个变化率来优化三个参数 $W_{in},W_{rec},W_{out}$。注意到 $\frac{\partial E}{\partial W_{in}} = \sum_t \frac{\partial E_t}{\partial W_{in}}$, 因此我们只要对每个时刻的损失函数求偏导数再加起来即可。矩阵求导有两种布局方式:分母布局(Denominator Layout)和分子布局(Numerator Layout),关于分子布局和分母布局的区别,请参考文献3。 如果这里采用分子布局,那么更新梯度时还需要将梯度矩阵进行一次转置,因此出于数学上的方便,后续的矩阵求导都将采用分母布局。
2.2 计算 $\frac{\partial E_t}{\partial W_{out}}$
注意到$E_t$是$W_{out}$的复合函数,参考文献3中Scalar-by-matrix identities一节中关于复合矩阵函数求导法则(右边的是分母布局):

我们有:
其中$r_t^{(i)}=(\hat{y}_t-y_t)^{(i)}$表示残差向量第$i$个分量,$h_t^{(j)}$表示$h_t$的第j个分量。
上述结果可以改写为:
其中$\otimes$表示向量外积。
2.3 计算$\frac{\partial E_t}{\partial W_{rec}}$
由于$W_{rec}$是各个时刻共享的,所以$t$时刻之前的每个时刻$W_{rec}$的变化都对$E_t$有贡献,反过来求偏导时,也要考虑之前每个时刻$W_{rec}$对$E$的影响。 我们以$s_k$为中间变量,应用链式法则:
但由于$\frac{\partial s_k}{\partial W_{rec}}$(分子向量,分母矩阵)以目前的数学发展水平是没办法求的, 因此我们要求这个偏导,可以拆解为$E_t$对$W_{rec}(i,j)$的偏导数:
其中,$\delta^{(t)}_k=\frac{\partial E_t}{\partial s_k}$,遵循
的传递关系。
应用链式法则有:
其中,$\odot$表示向量点乘(element-wise product)。注意$E_t$求导时链式法则的顺序,$E_t$是关于$s_k$的符合函数,且求导链上的每个变量都是向量, 根据参考文献3,这种情况下应用分母布局的链式法则,方向应该是相反的。
接下来计算$\delta^{(t)}_t$:
于是,我们得到了关于$\delta$ 的递推关系式:
由 $ \delta^{(t)}_t $ 出发, 我们可以往前推出每一个 $ \delta $ , 将 代入 有:
将上式写成矩阵形式:
不失严谨性,定义$h_{-1}$为全0的向量。
2.4 计算$\frac{\partial E_t}{\partial W_{in}}$
按照上述思路,我们可以得到
由于$x_k$是个one-hot vector,假设$x_k(m)=1$,那么我们在更新$W$时只需要更新$W$的第$m$列即可。
2.5 参数更新
我们有了$E_t$关于各个参数的偏导数,就可以用梯度下降来更新各参数了:
其中 ,
表示学习率。
2.6 部分思考
- 为什么RNN中要对隐藏层的输出进行一次运算$z_t=W_{out}h_t$,然后再对$z_t$进行一次softmax,而不是直接对$h_t$进行softmax求得概率?为什么要有$W_{out}$这个参数?
- 答:$x_t$是一个$K\times 1$的向量,我们要将它映射到一个$H\times 1$的$h_t$(其中$H$是隐神经元的个数),从$x_t$到$h_t$相当于对词向量做了一次编码;最终我们要得到的是一个$K\times 1$的向量(这里$K$是词汇表大小),表示每个词接下来出现的概率,所以我们需要一个矩阵$K\times H$的$W_{out}$来将$h_t$映射回原来的空间去,这个过程相当于解码。因此,RNN可以理解为一种编解码网络。
- $W_{in},W_{rec},W_{out}$三个参数分别有什么意义?
- 答: $W_{in}$将$K\times 1$的one-hot词向量映射到$H\times 1$隐藏层空间,将输入转化为计算机内部可理解可处理的形式,这个过程可以理解为一次编码过程;$W_{rec}$则是隐含层到自身的一个映射,它定义了模型如何结合上文信息,在编码中融入了之前的“记忆”;$W_{in},W_{rec}$结合了当前输入单词和之前的记忆,形成了当前时刻的知识状态。$W_{out}$是隐含层到输出的映射,$z=W_{out}h$是映射后的分数,这个过程相当于一次解码。这个解码后的分数再经过一层softmax转化为概率输出来,我们挑选概率最高的那个作为我们的预测。作为总结, RNN的记忆由两部分构成,一部分是当前的输入,另一部分是之前的记忆。
- BPTT和BP的区别在哪?为什么不能用BP算法训练RNN?
- 答:BP算法只考虑了误差的导数在上下层级之间梯度的反向传播;而BPTT则同时包含了梯度在纵向层级间的反向传播和在时间维度上的反向传播,同时在两个方向上进行参数优化。
- 文中词$x_t$的特征是一个one-hot vector,这里能不能替换为word2vec训练出的词向量?效果和性能如何?
- 答:RNNLM本身自带了训练词向量的过程。由于$x_t$是one-hot向量,假设出现的词的索引为$j$,那么$W_{in}x_t$就是把$W_{in}$的第$j$列$W[:,j]$取出,这个列向量就相当于该词的词向量。实际上用语言模型训练词向量的思想最早可以追溯到03年Bengio的一篇论文《A neural probabilistic language model 》,这篇论文中作者使用一个神经网络模型来训练n-gram模型,顺便学到了词向量。本文出于数学推导以及代码实现上的方便采用了one-hot向量作为输入。实际工程中,词汇表通常都是几百万,内存没办法装下几百万维的稠密矩阵,所以工程上基本上没有用one-hot的,基本都是用词向量。
>