GBDT & XGBoost
GBDT & XGBoost
目录
- 符号定义
- GBDT = GBRT = MART
- XGBoost
- 正则化
- GBDT与XGBoost的比较
1. 符号定义
决策树 \[ f(x; \lbrace R_j, b_j\rbrace ^{J}_1) = \sum_{j=1}^J b_j I(x\in R_j) \] \( \lbrace R_j \rbrace ^{J}_1 \)和\( \lbrace b_j \rbrace ^{J}_1 \)表示决策树的参数,前者为分段空间(disjoint空间),后者为这些空间上的输出值[其他地方称为打分值],\(J\)是叶子结点的数量,下文中用\(f(x)\)省略表示\( f(x; \lbrace R_j, b_j\rbrace ^{J}_1) \)
决策树的Ensemble \[ F = \sum_{i=0}^K f_i \] 其中\(f_0\)是模型初始值,通常为统计样本计算出的常数[论文中为median],同时定义\( F_k = \sum_{i=0}^k f_i \)。
\(D = \lbrace (x_i, y_i) \rbrace ^N_1\),训练样本。
\[ \mathfrak{L} = \mathfrak{L}( \lbrace y_i, F(x_i) \rbrace ^N_1 ) = \underbrace{\sum_{i=1}^N L(y_i, F(x_i))}_{\text{训练误差项}} + \underbrace{\sum_{k=1}^K \Omega(f_k)}_{\text{正则化项}} \] 目标函数(损失函数),第一项\(L\)是针对训练数据的\(Loss\),可以选择:绝对值误差、平方误差、logistic loss等;第二项\( \Omega \)是正则化函数,惩罚\(f_k\)的复杂度。
2. GBDT
2.1 算法1 - GBDT算法[论文中:Algorithm1:Gradient Boost]
输入:\( \lbrace (x_i, y_i) \rbrace^N_1 , K, L, …\)
输出:\(F_k\)
(1)初始化\(f_0\)
(2)对k=1,2,…,K, 计算
(2.1)\( \tilde{y}_i = - \frac{\partial L(y_i, F_{k-1}(x_i))}{\partial F_{k-1}}, i=1,2,…,N \)
计算响应[response]\(\tilde{y}_i\),它是一个和残差[residual, \(y_i-F_{k-1}(x_i)\)]正相关的变量。
(2.2)\( \lbrace R_j, b_j \rbrace^{J^{\ast}}_1 = \mathop{\arg\min}_{\lbrace R_j, b_j \rbrace^J_1} \sum_{i=1}^N [\tilde{y}_i - f_k(x_i;\lbrace R_j,b_j \rbrace^J_1)]^2 \)
使用平方误差训练一颗决策树\(f_k\),拟合数据\( \lbrace (x_i, \tilde{y}_i) \rbrace^N_1 \)
(2.3)\( \rho^{\ast} = \mathop{\arg\min}_{\rho} \mathfrak{L}(\lbrace y_i, F_{k-1}(x_i)+\rho f_k(x_i) \rbrace ^N_1)= \mathop{\arg\min}_{\rho} \sum_{i=1}^N L(y_i, F_{k-1}(x_i) + \rho f _k(x_i)) + \Omega(f_k) \)
求一个步长\(\rho^{\ast}\),最小化损失。
(2.4)令\( f_k = \rho^{\ast}f_k, \quad F_k = F_{k-1}+f_k \)
将训练出来的\(f_k\)叠加到\(F\)。
总体来说,GBDT就是一个不断拟合响应(残差)并叠加到F上的过程,在这个过程中,响应不断变小,Loss不断接近最小值。
2.2 GBDT例子
GBDT的核心就在于,每一棵树学的是之前所有树结论和的残差,这个残差就是一个加预测值后能得真实值的累加量。比如A的真实年龄是18岁,但第一棵树的预测年龄是12岁,差了6岁,即残差为6岁。那么在第二棵树里我们把A的年龄设为6岁去学习,如果第二棵树真的能把A分到6岁的叶子节点,那累加两棵树的结论就是A的真实年龄;如果第二棵树的结论是5岁,则A仍然存在1岁的残差,第三棵树里A的年龄就变成1岁,继续学。这就是Gradient Boosting在GBDT中的意义。
假设我们现在有一个训练集,训练集只有4个人A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。如果是用一棵传统的回归决策树来训练,会得到如下图所示结果:
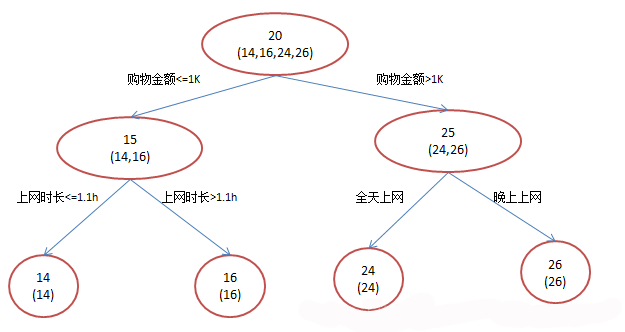
现在我们使用GBDT来做这件事,由于数据太少,我们限定叶子节点做多有两个,即每棵树都只有一个分枝,并且限定只学两棵树。我们会得到如下图所示结果:
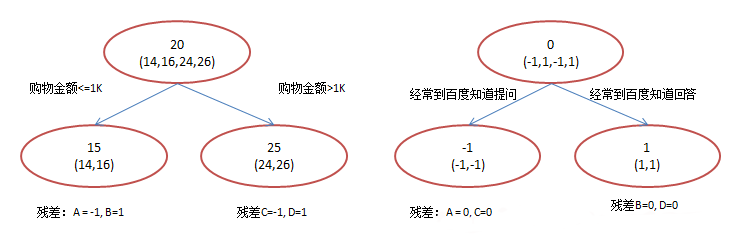
在第一棵树分枝和第一张图片中一样,由于A,B年龄较为相近,C,D年龄较为相近,他们被分为两拨,每拨用平均年龄作为预测值。此时计算残差(残差的意思就是: A的预测值 + A的残差 = A的实际值),所以A的残差就是16-15=1(注意,A的预测值是指前面所有树累加的和,这里前面只有一棵树所以直接是15,如果还有树则需要都累加起来作为A的预测值)。进而得到A,B,C,D的残差分别为-1,1,-1,1。然后我们拿残差替代A,B,C,D的原值,到第二棵树去学习,如果我们的预测值和它们的残差相等,则只需把第二棵树的结论累加到第一棵树上就能得到真实年龄了。这里的数据显然是可以做的,第二棵树只有两个值1和-1,直接分成两个节点。此时所有人的残差都是0,即每个人都得到了真实的预测值。
最后GBDT的预测结果为:
- A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14;
- B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16;
- C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24;
- D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26。
那么哪里体现了Gradient呢?其实回到第一棵树结束时想一想,无论此时的cost function是什么,是均方差还是均差,只要它以误差作为衡量标准,残差向量(-1, 1, -1, 1)都是它的全局最优方向,这就是Gradient。
注:两张图片中的最终效果相同,为何还需要GBDT呢?答案是过拟合。
其他例子请见李航博士《统计学习方法》page.149
GBRT 的优点:
- 对混合型数据的自然处理(异构特征)
- 强大的预测能力
- 在输出空间中对异常点的鲁棒性(通过具有鲁棒性的损失函数实现)
GBDT 的缺点:
- 可扩展性差(校对者注:此处的可扩展性特指在更大规模的数据集/复杂度更高的模型上使用的能力,而非我们通常说的功能的扩展性;GBDT 支持自定义的损失函数,从这个角度看它的扩展性还是很强的!)。由于提升算法的有序性(也就是说下一步的结果依赖于上一步),因此很难做并行.
附GBDT论文Friedman J. - Greedy Function Approximation_A Gradient Boosting Machine
3. XGBoost
xgboost中使用的正则化函数为: \[ \Omega(f_k) = \frac{\gamma}{2} J + \frac{\lambda}{2} \sum_{j=1}^J b^2_j \] 我们的目标是求\(f_k\),它最小化目标函数[式\(3\)] \[ \begin{equation} \begin{aligned} \mathfrak{L}_k & = \sum_{i=1}^N L(y_i, F_{k-1}(x_i)+ \rho f_k(x_i)) + \Omega(f_k) \\ & = \sum_{i=1}^N L(y_i, F_{k-1}+\rho f_k) + \Omega(f_k) \quad \quad \quad [泰勒二阶展开可得下步] \\ & \approx \sum_{i=1}^N \lgroup L(y_i, F_{k-1}) + \underbrace{\frac{\partial L(y_i, F_{k-1})}{\partial F_{k-1}}}_{\text{= \(g_i\)}} f_k + \frac{1}{2}\underbrace{\frac{\partial^2 L(y_i, F_{k-1})}{\partial F^2_{k-1}}}_{\text{=\(h_i\)}} f^2_k \rgroup + \Omega(f_k) \\ & = \sum_{i=1}^N \lgroup L(y_i, F_{k-1}) + g_i f_k + \frac{1}{2}h_i f_k^2 \rgroup + \Omega(f_k) \\ & = \sum_{i=1}^N \lgroup L(y_i, F_{k-1}) + g_i \sum_{j=1}^J b_j + \frac{1}{2} h_i \sum_{j=1}^J b_j^2 \rgroup + \frac{\gamma}{2} J + \frac{\lambda}{2} \sum_{j=1}^J b_j^2 \\ \end{aligned} \end{equation} \] 整理出和\(\lbrace R_j \rbrace^J_1, \lbrace b_j \rbrace^J_1\)有关的项: \[ \begin{equation} \begin{aligned} \mathfrak{L}(\lbrace R_j \rbrace^J_1, \lbrace b_j \rbrace^J_1) & = \sum_{i=1}^N \lgroup g_i \sum_{j=1}^J b_j + \frac{1}{2}h_i \sum_{j=1}^J b_j^2 \rgroup + \frac{\gamma}{2} J + \frac{\lambda}{2} \sum_{j=1}^J b_j^2 \\ & = \sum_{x_i \in R_j} \lgroup g_i \sum_{j=1}^J b_j + \frac{1}{2}h_i \sum_{j=1}^J b_j^2 \rgroup + \frac{\gamma}{2} J + \frac{\lambda}{2} \sum_{j=1}^J b_j^2 \\ & = \sum_{j=1}^J \lgroup \sum_{x_i \in R_j} g_i b_j + \sum_{x_i \in R_j} \frac{1}{2} h_i b_j^2 \rgroup + \frac{\gamma}{2} J + \frac{\lambda}{2} \sum_{j=1}^J b_j^2 \\ & = \sum_{j=1}^J \lgroup \underbrace{\sum_{x_i \in R_j}g_i}_{\text{\(=G_j\)}}b_j + \frac{1}{2} \lgroup \underbrace{\sum_{x_i \in R_j}h_i}_{\text{\(=H_j \)}} + \lambda \rgroup b_j^2 \rgroup + \frac{\gamma}{2} J \\ & = \sum_{j=1}^J \lgroup G_jb_j + \frac{1}{2}(H_j + \lambda)b_j^2 \rgroup + \frac{\gamma}{2} J \end{aligned} \end{equation} \] \(式(6)\)对\(b_j\)求导,并令其等于零,得: \[ b_j^{\ast} = - \frac{G_j}{H_j + \lambda}, \quad j=1,2,…,J \] \(式(7)代入式(6)\)中,化简得最小的\(\mathfrak{L}\): \[ \mathfrak{L}^{\ast}_k = - \frac{1}{2} \sum_{j=1}^J \frac{G_j^2}{H_j+\lambda} + \frac{\gamma}{2}J \]
求\(\lbrace R_j\rbrace^J_1\)与求\( \lbrace b_j \rbrace^J_1 \)的方法不同,前者它是对输入\(x\)所属空间的一种划分方法不连续,无法求导。 精确得到划分\(\lbrace R_j \rbrace^J_1\)是一个NP难问 题,取而代之使用贪心法,即分裂某节点时,只考虑对当前节点分裂后哪个分裂方案能得到最小的\(\mathfrak{L}_k\)。 像传统决策树一样,CART中的办法也是遍历\(x\)的每个维度的每个分裂点,选择具有最小 $\mathfrak{L}_k$的维度和分裂点进行。 那么定义:当前节点 $R_j$ 分裂成\( R_L \)和\( R_R \)使得分裂后整棵树的\( \mathfrak{L}_k \)最小。
从\(式(8)\)可知,整棵树的最小\(\mathfrak{L}_k\)等于每个叶子结点上(最小)Loss的和,由于整个分裂过程中只涉及到3个结点,其他任何结点的Loss在分裂过程中不变,这个问题等价于: \[ \mathop{\max}_{R_L, R_R} \frac{G_L^2}{H_L+\lambda} + \frac{G_R^2}{H_R+\lambda} - \frac{(G_L+G_R)^2}{H_L+H_R+\lambda} - \frac{\gamma}{2} \] \(式(9)\)的含义是:前两项分别加上新生成的叶子结点的最小Loss,第三项是指减去被分裂的叶子结点的最小Loss,第四项是分裂后增加叶结点带来的模型复杂度。它是将结点\(R_j\)分裂成\(R_L和R_R\)后,整棵树最小\(\mathfrak{L}_k\)的降低量,这个量越大越好。
3.1 xgboost树的分裂算法

3.2 xgboost调参
1-Complete Guide to Parameter Tuning in XGBoost
4. 正则化
GBDT有非常快降低Loss的能力,这也会造成一个问题:Loss迅速下降,模型低bias,高variance,造成过拟合。
下面一一介绍GBDT中抵抗过拟合的技巧:
- 限制树的复杂度。\(\Omega\)函数对树的节点数,和节点上预测值\( \lbrace b_j \rbrace^J_1 \)的平方和均有惩罚,除此之外,我们通常在终止条件上还会增加一条为树的深度。
- 采样。即训练每个树的时候只使用一部分的样本。
- 列采样。即训练每个树的时候只使用一部分的特征,这是Xgboost的创新,它将随机森林中的思想引入了GBDT。
- Shrinkage。进一步惩罚\(\lbrace b_j \rbrace^J_1\),给它们乘一个小于1的系数,也可以理解为设置了一个较低的学习率。
- Early stop。因为GBDT的可叠加性我们使用的模型不一定是最终的ensemble,而根据测试集的测试情况,选择使用前若干棵树。
5. GBDT与XGBoost的比较
以下来自知乎,作者:wepon
- 传统GBDT以CART作为基分类器,xgboost还支持线性分类器,这个时候xgboost相当于带L1和L2正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。
- 传统GBDT在优化时只用到一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶和二阶导数。顺便提一下,xgboost工具支持自定义代价函数,只要函数可一阶和二阶求导。
- xgboost在代价函数里加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的score的L2模的平方和。从Bias-variance tradeoff角度来讲,正则项降低了模型的variance,使学习出来的模型更加简单,防止过拟合,这也是xgboost优于传统GBDT的一个特性。
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。实际应用中,一般把eta设置得小一点,然后迭代次数设置得大一点。(补充:传统GBDT的实现也有学习速率)
- 列抽样(column subsampling)。xgboost借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算,这也是xgboost异于传统gbdt的一个特性。
- 对缺失值的处理。对于特征的值有缺失的样本,xgboost可以自动学习出它的分裂方向。
- xgboost工具支持并行。boosting不是一种串行的结构吗?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。xgboost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),xgboost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
- 可并行的近似直方图算法。树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以xgboost还提出了一种可并行的近似直方图算法,用于高效地生成候选的分割点。
- 为了限制树的生长,加入阈值gamma,当增益大于阈值时才让节点分裂,它是正则项里叶子节点数J的系数,所以xgboost在优化目标函数的同时相当于做了预剪枝。另外,上式中还有一个系数lambda,是正则项里leaf score的L2模平方的系数,对leaf score做了平滑,也起到了防止过拟合的作用,这个是传统GBDT里不具备的特性
参考
Friedman - Greedy Function Approximation:A Gradient Boosting Machine