使用sklearn大规模机器学习
[转]使用sklearn大规模机器学习
目录
- 核外学习(out-of-core learning)
- 磁盘上数据流式化
- sklearn 中的 SGD
- 流式数据中的特征工程
- 总结
转载自:吴良超的学习笔记
核外学习(out-of-core learning)
核外学习指的是机器的内存无法容纳训练的数据集,但是硬盘可容纳这些数据,这种情况在数据集较大的时候比较常见,一般有两种解决方法:sampling 与 mini-batch learning。
sampling(采样)
采样可以针对样本数目或样本特征,能够减少样本的数量或者feature的数目,两者均能减小整个数据集所占内存,但是采样无可避免地会丢失掉原来数据集中的一些信息(当数据没有冗余的时候),这会导致 variance inflation 问题,也就是进行若干次采样,每次训练得出的模型之间差异都比较大。用 bias-variance 来解释就是出现了high variance,原因是每次采样得到的数据中都有随机噪声,而模型拟合了这些没有规律的噪声,从而导致了每次得到的模型都不一样。
解决采样带来的 high-variance 问题,可以通过训练多个采样模型,然后将其进行集成,采用这种思路典型的方法有 bagging。
mini-batch learning(小批量学习/增量学习)
这种方法不同于 sampling,利用了全部的数据,只是每次只用一部分样本(可以是一个样本,也可以是多个样本)来训练模型,通过增加迭代的次数可以近似用全部数据集训练的效果,这种方法需要训练的算法的支持,SGD 恰好就能够提供这种模式的训练,因此 SGD 是这种模式训练的核心。下面也主要针对这种方法进行讲述。
通过 SGD 进行训练时,需要流式(streaming)读取训练样本,同时注意的是要将样本的顺序随机打乱,以消除样本顺序带来的信息(如先用正样本训练,再用负样本训练,模型会偏向于将样本预测为负)。下面主要讲述如何将磁盘上的数据流式化并送入到模型中进行训练。
磁盘上数据流式化
文件读取
这里读取的数据的格式是每行存储一个样本。最简单的方法就是通过 python 读取文件的 readline 方法实现
1 | with open(source_file, 'r') as fp: |
而往往训练文件都是 csv 格式的,此时需要丢弃第一行,同时可通过 csv 模块进行读取, 下面以这个数据文件为例说明: Bike-Sharing-Dataset.zip 备用地址:Bike-Sharing-Dataset.zip,
1 | import csv |
输出为
1 | Total rows: 17380 |
在上面的例子中,每个样本是就是一个 row(list类型),样本的 feature 只能通过 row[index] 方式获取,假如要通过 header 中的名称获取, 可以修改上面获取 iterator 的代码,用 csv.DictReader(f, delimiter = SEP) 来获取 iterator,此时得到的 row 会是一个 dictionary,key 为 header 中的列名,value 为对应的值; 对应的代码为
1 | import csv |
输出为
1 | Total rows: 17379 |
除了通过 csv 模块进行读取,还可以通过 pandas 模块进行读取,pandas 模块可以说是处理 csv 文件的神器,csv 每次只能读取一条数据,而 pandas 可以指定每次读取的数据的数目,如下所示:
1 | import pandas as pd |
对应的输出为
1 | Size of uploaded chunk: 1000 instances, 17 features |
数据库读取
上面的是直接从文件中读取的数据,但是数据也可能存在数据库中,因为通过数据库不仅能够有效进行增删查改等操作,而且通过 Database Normalization 能够在不丢失信息的基础上减少数据冗余性。
假设上面的数据已经存储在 SQLite 数据库中,则流式读取的方法如下(未验证)
1 | import sqlite3 |
输出为
1 | Chunk 1 - Size of uploaded chunk: 2500 istances, 18 features |
样本的读取顺序
上面简单提到了通过 SGD 训练模型的时候,需要注意样本的顺序必须要是随机打乱的。
假如给定一批样本,然后用整批的样本来更新,那么就不存在样本的读取顺序问题;但是由于像 SGD 这种 online learning 的训练模式,越是后面才读取的样本,模型一般会拟合得更好,因为这是模型最近看到了这些样本且针对这些样本进行了调整。
这样的特性有其好处,如处理时间序列的数据时,由于对最近时间的数据拟合得更好,因此不会受到时间太久远的数据的影响,但是在更多的情况下,这种由样本顺序带来的是有弊无益的,如上面提到的先用全部的正样本训练,再用全部的负样本训练。因此有必要对数据先进行 shuffle ,然后再通过 SGD 来进行训练。
假如内存能够容纳这些数据,那么所有的数据可以在内存中进行一次 shuffle;假如无法容纳,则可以将整个大的数据文件分为若干个小的文件,分别进行 shuffle ,然后再拼接起来,拼接时也不按照原来的顺序,而是进行 shuffle 后再拼接,下面是这两种 shuffle 方法的实现代码。
在内存中进行 shuffle 之前可以通过 zlib 对样本先进行压缩,从而让内存可以容纳更多的样本,实现代码如下
1 | import zlib |
基于磁盘的 shuffle 方法首先将整个文件划分为若干个小文件,然后再进行 shuffle, 为了能够实现整个数据集更彻底的 shuffle ,可以将上面的过程重复几遍,同时每次都改变划分的文件的大小,实现的代码如下
1 | from random import shuffle |
sklearn 中的 SGD
通过前面的步骤可以将数据以流式输入,下面接着就是要通过 SGD 进行训练,在 sklearn 中, sklearn.linear_model.SGDClassifier 和 sklearn.linear_model.SGDRegressor 均是通过 SGD 实现,只是一个用于分类,一个用于回归。下面以 sklearn.linear_model.SGDClassifier 为例进行简单说明,更详细的内容可参考其官方文档。这里仅对其几个参数和方法进行简单的讲解。
需要注意的参数有:
- loss : 表示具体的分类器,可选的值为 hinge、log、modified_huber、squared_hinge、perceptron;如 hinge 表示 SVM 分类器,log 表示logistics regression等
- penalty:正则项,用于防止过拟合(默认为 L2 正则项)
- learning_rate: 表示选择哪种学习速率方案,共有三种:constant、optimal、invscaling,各种详细含义可参考官方文档
- 需要注意的方法主要就是 partial_fit(X, y, classes), X 和 y 是每次流式输入的数据,而 classes 则是具体的分类数目, 若 classes 数目大于2,则会根据 one-vs-rest 规则训练多个分类器。
需要注意的是 partial_fit 只会对数据遍历一次,需要自己显式指定遍历的次数,如下是使用 sklearn 中的 SGDClassfier 的一个简单例子。
1 | from sklearn import linear_model |
流式数据中的特征工程
feature scaling
对于 SGD 算法,特征的 scaling 会影响其优化过程,也就是只有将特征标准化(均值为0,方差为1)或归一化(处于 [0,1] 内)才能加快算法收敛的速度,但是由于数据不能一次读入内存,如果需要标准化或归一化,需要对数据遍历 2 次,第一次遍历是为了求特征的均值和方差(标准化需要)或最大最小值(归一化需要),第二次遍历便可以用上面的均值、方差、最大值,最小值等值进行标准化。
由于数据是流式输入的,求解均值、最大值、最小值都没有什么问题,但是求解方差的公式为(\(\mu\)为均值): \[ \sigma ^2= \frac{1}{n} \sum_x (x−μ)^2 \]
只有知道均值才能求解,这意味着只有遍历一次求得\(\mu\)后才能求\(\sigma^2\),这无疑会增加求解的时间,下面对这个公式进行简单的变换,使得\(\mu和 \sigma^2 \)能够同时求出。假如当前有 n 个样本,当前的均值 \( \mu’ \) 可以简单求出,而当前的方差 \( \sigma’^2 \) 可通以下公式求解 \[ \sigma′^2 = \frac{1}{n} \sum_x (x^2 − 2 x \mu′+\mu′^2 ) = \frac{1}{n} \sum_x (x^2) − \frac{1}{n} (2n\mu′^2 − n \mu′^2)=\frac{1}{n}\sum_x (x^2) − \mu′^2 \]
通过这个公式,可以遍历一次便求出任意个样本的方差,下面通过这个公式求解均值和方差随着样本数量变化而变化的情况,并比较进行 shuffle 前后两者在均值和方差上的区别。
1 | # calculate the running mean,standard deviation, and range reporting the final result |
输出如下
1 | ===========raw data file=========== |
两者的统计数据一致,符合要求,下面再看看两者的均值和方差随着时间如何变化,也就是将上面得到的 running_mean 和 running_std 进行可视化
1 | # plot how such stats changed as data was streamed from disk |
得到的结果如下
原始的文件
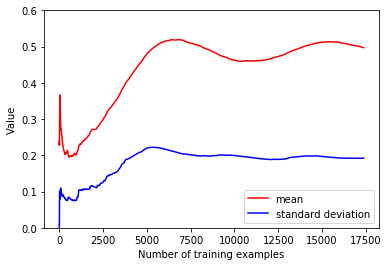
shuffle 后的文件
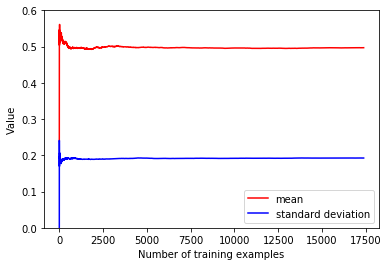
可以看到,经过 shuffle 后的数据的均值和方差很快就达到了稳定的状态,可以让 SGD 算法更快地收敛,这也从另一个角度验证了 shuffle 的必要性。
hasing trick
对于 categorial feature, 往往要对其进行 one-hot 编码,但是进行 one-hot 编码需要知道这个 feature 所有可能的取值的数量,对于流式输入的数据,可以先遍历一遍数据得到 categorial feature 所有可能取值的数目。除此之外,还可以利用接下来要讲的 hashing trick 对categorical feature 进行 one-hot 编码,这种方法对只能遍历一遍的数据有效。
hahsing trick 利用了 hash 函数,通过hash后取模,将样本的值映射到预先定义好的固定长度的槽列中的某个槽中,这种方法需要对 categorical feature 的所有可能取值有大概的估计,而且可能会出现冲突的情况,但是如果对categorical feature 的所有可能取值有较准确的估计时,冲突的概率会比较低。下面是利用 sklearn 中的 HashingVectorizer 进行这种编码的一个例子
1 | from sklearn.feature_extraction.text import HashingVectorizer |
输出如下
1 | (0, 61) 1.0 |
这里定义的槽列的长度为1000,即假设字典中的单词数目为 1000, 然后将文本映射到这个槽列中,1 表示有这个单词,0表示没有。
总结
本文主要介绍了如何进行 out-of-core learning,主要思想就是将数据以流式方式读入,然后通过 SGD 算法进行更新, 在读入数据之前,首先需要对数据进行 shuffle 操作,消除数据本来的顺序信息等,同时可以让样本的特征的方差和均值更快达到稳定状态。